Compare AI Models
Side by Side
Stop guessing which AI is best. Compare GPT, Claude, Gemini, DeepSeek, and 100+ models on YOUR actual task — with real API costs and deterministic scoring.
How it works: Write a prompt, select models, click benchmark. OpenMark sends identical requests to every model, scores them deterministically, and shows you who wins — on YOUR task, not a generic test.
Why Comparing AI Models Is Hard
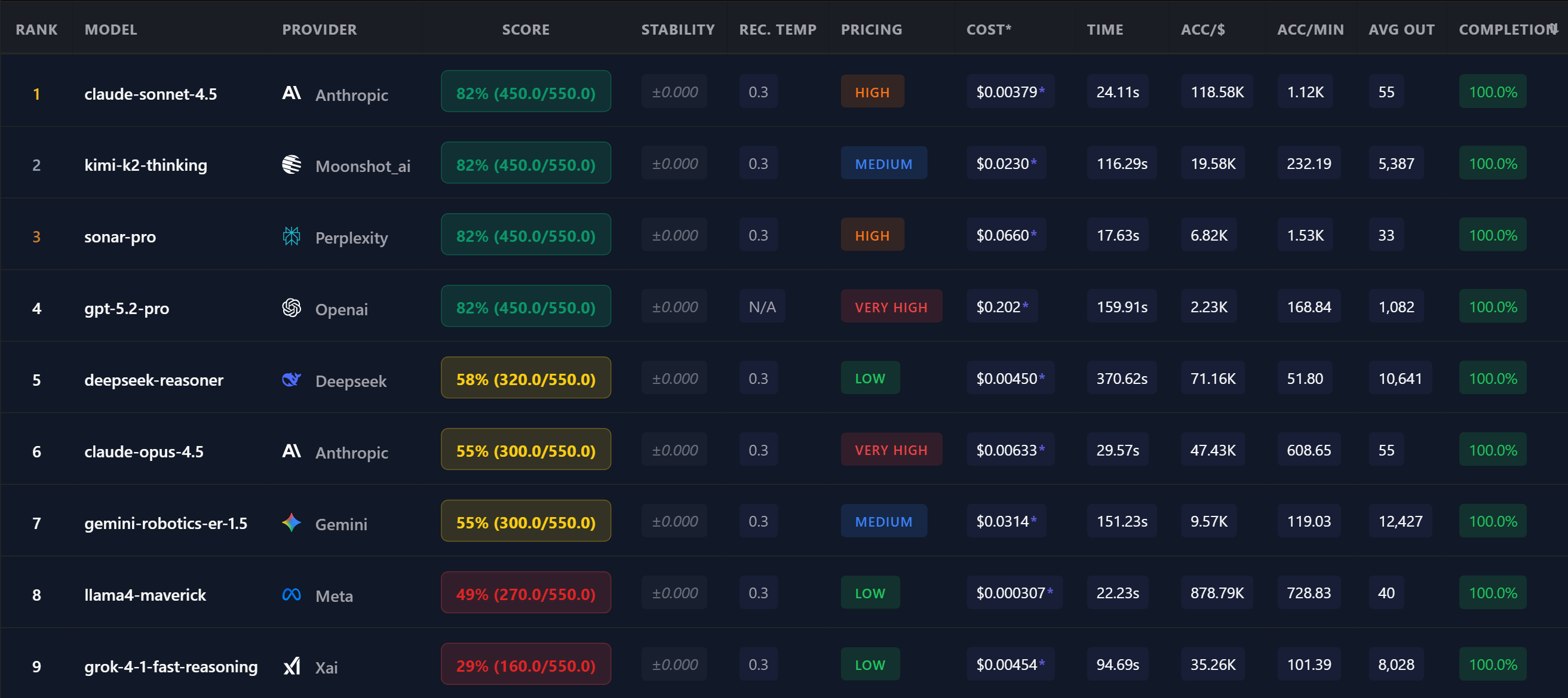
There are 100+ AI models from 15+ providers. New ones launch every week. Each provider claims their model is "state-of-the-art." The reality? Performance varies wildly depending on your specific task.
A model that tops the MMLU leaderboard might fail at your customer support automation. The cheapest model might outperform the most expensive one for your data extraction pipeline. You simply can't know without testing.
The Old Way
Read blog posts, check leaderboards, try models one by one, eyeball results, guess which is best. Takes hours. No real data.
The OpenMark Way
Write your task once, run it against all models simultaneously. Get accuracy, cost, speed, and stability data in minutes.
What You Can Compare
OpenMark doesn't just compare models — it compares them on what matters for YOUR use case:
Accuracy
Deterministic scoring — same result every run. No LLM-as-judge, no vibes.
Cost per Task
Real API costs based on actual token usage. Not just per-token rates.
Speed
Response latency measured per model. Find the fastest option for real-time apps.
Stability
Run multiple times to see consistency. Some models swing 30% between runs.
Accuracy per Dollar
The metric that actually matters. Which model gives you the most accuracy for your budget?
Temperature
Automatically find the optimal temperature setting for your task across models.
Models You Can Compare
OpenMark includes every major AI provider. Compare flagship and budget models in one benchmark:
"We compared 12 models on our legal contract analysis task. The #1 model on the MMLU leaderboard came in 5th. A model costing 90% less came in 2nd. You can't know without benchmarking."
How to Compare AI Models on OpenMark
Frequently Asked Questions
How is this different from ChatBot Arena?
ChatBot Arena uses human voting on generic prompts — subjective and not task-specific. OpenMark uses deterministic scoring on YOUR actual prompts. Same result every time, with cost and speed data.
Can I compare more than 2 models at once?
Yes — you can benchmark up to 20+ models simultaneously. OpenMark sends identical requests to all selected models in parallel and ranks them in a sortable results table.
Is it free to compare AI models?
Yes. Sign up and get 50 free credits. Each benchmark costs a small number of credits based on the models and output tokens used. See pricing details →
Can you run the benchmark for me?
Yes. The audit service ($299–$499) covers one recurring task across 10–20 models in 48 hours. Optional retainer at $500–$1,000/month for ongoing re-runs as new models ship. Best-fit for tasks with measurable outputs (classification, extraction, RAG grading, routing, moderation). Details on the audit page →
Why Teams Use OpenMark AI
Not just the big 3. Compare models from every major provider in the same run — all in one place.
Every benchmark hits live APIs and returns actual tokens, actual latency, actual costs. Not cached or self-reported.
Structured, repeatable metrics you can trust. Not LLM-as-judge, where the evaluator is as unreliable as what's being evaluated.
No accounts with providers required. OpenMark AI handles every API call — just describe your task and run.
Don't want to design the test yourself? Have us run it for you.
If you're researching which model to ship and want a definitive answer for your task instead of more reading — we run the eval for you. Send us your task, we benchmark it across all relevant models (up to 30+) and send back a synthesized report with the recommended primary, fallbacks, cost-at-volume, and re-test triggers. From $299, 48-hour turnaround, no call required.
Compare AI Models on YOUR Task
100+ models. Real costs. Deterministic scoring.
Free tier — no credit card required.