The Model You Use Might Be Costing You 10x Too Much
Generic leaderboards don't tell you which LLM works for YOUR task. The only way to know is to test your actual use case.
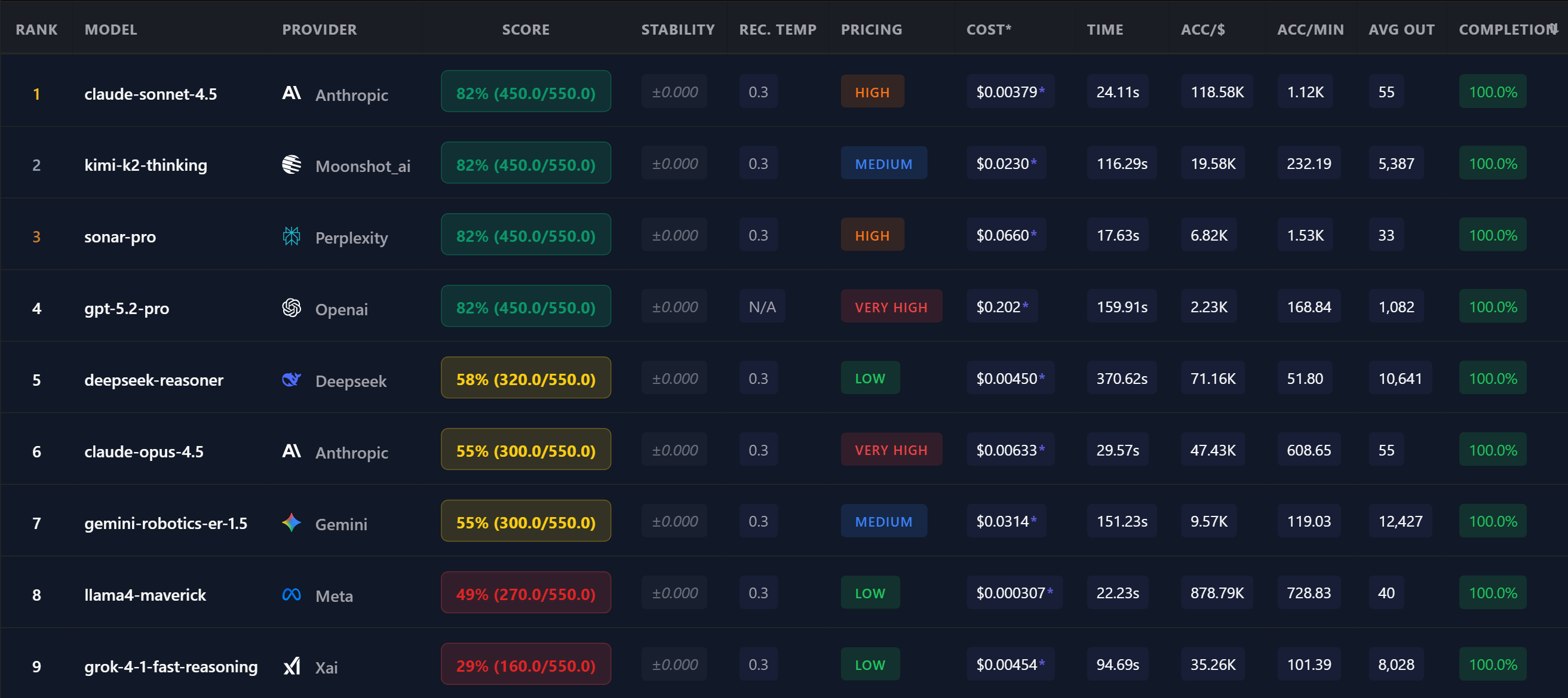
The Problem with Current AI Benchmarks
When you need to choose an LLM for production, where do you look? MMLU scores? LMArena rankings? These benchmarks have a fundamental problem: they don't measure what matters for your specific use case.
MMLU, HumanEval, and friends
Models are increasingly "benchmark-maxed" — trained to score well on these specific tests without generalizing. High scores don't predict real-world performance on your task.
Using AI to evaluate AI
Non-reproducible, subjective, and circular. Who judges the judge? Results vary between runs, making comparison impossible.
LMArena and similar systems
Vibes-based, non-deterministic, and not task-specific. "Which response feels better" doesn't tell you which model handles YOUR task.
"I was building a RAG pipeline and assumed the most 'advanced' model would be the best fit. After testing models against my actual workload, a less popular option performed better at a fraction of the cost. Relying on reputation alone would have led to a costly mistake. This is what led to OpenMark."
See It In Action
From task to ranked results — OpenMark explained in 90 seconds. Sound on.
How OpenMark Compares AI Models Differently
OpenMark is a deterministic LLM benchmarking platform. You define your task, run it against up to 100 models, and get reproducible, objective results. No guessing. No vibes.
Your Task, Your Benchmark
Define custom test cases with your actual prompts and expected outputs. Test what matters to you, not what model creators want to show off.
Deterministic Scoring
Multiple scoring modes to match your needs. Run the same test twice, get the same result. Reproducible, objective, and built for production decisions.
Real Cost Calculations
See actual API costs per task. Discover that cheaper models often outperform expensive ones for specific use cases. Optimize for accuracy-per-dollar, speed, or both.
Stability Metrics
Measure consistency across multiple runs. Some models are highly variable — critical to know before production deployment.
Temperature Discovery
Automatically find the optimal temperature setting for your task. Test multiple variants and get a recommendation based on accuracy and consistency.
Easy to Start, Powerful When Needed
Describe what you want to test in plain language — our AI agent generates the benchmark for you. Beginner-friendly, yet capable of deep, complex use. Free tier available.
When to Benchmark LLMs
Choosing a model for production: Test candidates on your actual task before committing. Find the best accuracy-to-cost ratio for your specific use case.
Monitoring model drift: AI providers update models silently. A model that worked last month might behave differently today. Regular benchmarking catches drift before it becomes a production issue.
Validating prompt robustness: If your prompt works consistently across multiple models, it's well-crafted. If it fails on most, you've found a fragility to fix.
Building your model routing map: Running agentic workflows or multi-step pipelines? Benchmark each step independently — pick the most cost-efficient model per step and create a deterministic routing map. When new models release, re-run your benchmarks and update your map in minutes.
Preparing fallbacks: Rate limits, downtime, API errors happen. Know your backup options before your primary goes down. Switch instantly to your best next option instead of scrambling.
Evaluating new model releases: When a new model drops, don't assume it's better for your task. GPT-5.4 scored the same as GPT-5.2 Pro at 2.2x the cost on some tasks. Gemini 3.1 Flash Lite matches flagship models at a fraction of the price for simpler steps. Test before you switch.
Frequently Asked Questions
How do I compare AI models for my use case?
Define your task with example prompts and expected outputs, then select which models to test. OpenMark runs your benchmark and ranks them by accuracy, cost, and speed for YOUR specific task.
How do I compare AI model pricing?
OpenMark calculates real API costs per task based on actual token usage. Compare GPT, Claude, Gemini, and other LLM pricing to find the best accuracy-per-dollar ratio.
Which AI model is best for my task?
It depends on your specific requirements. Define your prompts, select models to compare, and run a benchmark. Many users discover that smaller, cheaper models outperform flagship ones for their particular task.
How is this different from LLM leaderboards?
Public benchmarks like MMLU test generic tasks. OpenMark is an LLM benchmarking tool that lets you create custom benchmarks with YOUR prompts and deterministic scoring — no LLM-as-judge, no voting.
What makes this AI benchmark tool different?
OpenMark is an AI model comparison platform focused on real-world performance. You get deterministic scores, actual API costs, and stability metrics — not vibes or crowd voting.
Can I use this for model routing and orchestration?
Yes. Benchmark each step of your AI pipeline independently, pick the most cost-efficient model per step, and create a deterministic routing map. Re-run benchmarks when new models release to keep your routing optimal.
Can I test multi-step reasoning?
Yes. Use pipeline variables to chain prompts and test multi-step workflows. Compare how different AI models handle sequential reasoning across your actual use case.
Is there a free tier?
Yes. Sign up and get 50 free credits to test AI model comparison and LLM benchmarking. No credit card required.
Can you run the benchmark for me?
Yes. The audit service ($299–$499) covers one recurring task across 10–20 models in 48 hours. Optional retainer at $500–$1,000/month for ongoing re-runs as new models ship. Best-fit for tasks with measurable outputs (classification, extraction, RAG grading, routing, moderation). Details on the audit page →
Why Teams Use OpenMark AI
No accounts with OpenAI, Anthropic, or Google required. OpenMark AI handles every API call — just describe your task and run.
No Python SDK, no CLI, no notebook. Works for PMs, founders, and teams that don't want to spin up an eval pipeline.
Compare models from every major provider in a single benchmark run. Not 4, not "the big 3" — over 100.
Every benchmark hits live APIs and returns actual tokens, actual latency, actual costs. Not cached or self-reported.
Don't want to design the test yourself? Have us run it for you.
If reading this convinced you that custom benchmarking matters but you don't have a week to design one — we run it for you. Send us your task, we benchmark it across all relevant models (up to 30+) and send back a synthesized report with the recommended primary, fallbacks, cost-at-volume, and re-test triggers. From $299, 48-hour turnaround, no call required.
Find Out If You're Overpaying
Run your first benchmark in 2 minutes. Compare models on YOUR task — free.