LLM Benchmark Tool
for Your Actual Task
Generic benchmarks like MMLU and HumanEval don't test what matters for YOUR use case. OpenMark lets you benchmark 100+ LLMs on your own prompts with deterministic scoring.
Why Generic LLM Benchmarks Fall Short
MMLU tests college Q&A. HumanEval tests 164 Python functions. GPQA tests graduate-level science. These benchmarks are useful for researchers, but they don't tell you which model works best for your customer support bot, your data pipeline, your content generation system, or your agentic workflow.
Benchmark Contamination
Models may have seen test data during training. Scores look better than real-world performance. A model scoring 90% on MMLU might score 60% on your task.
Task Mismatch
Your legal contract review, medical analysis, or code migration has nothing in common with standardized tests. Generic benchmarks test generic skills.
Missing Cost Data
Leaderboards rank by accuracy but ignore that a "better" model might cost 50x more per task. For production workloads, cost matters as much as quality.
No Stability Metrics
A model averaging 85% accuracy might swing between 65% and 100%. For production, you need consistent results — not just high averages.
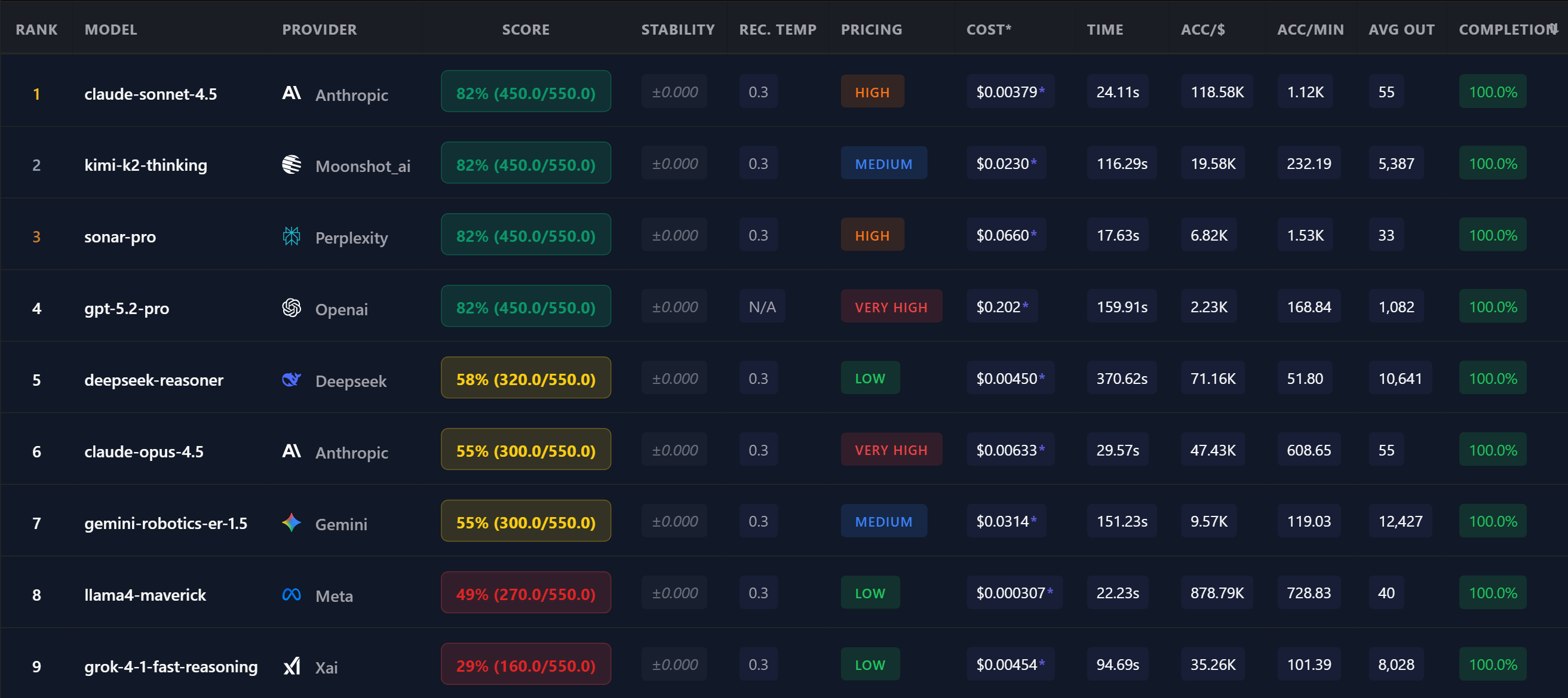
How OpenMark Benchmarking Works
OpenMark is a custom LLM benchmarking tool that tests models on YOUR prompts:
18 Scoring Modes for Any Task
OpenMark supports 18 deterministic scoring modes — no LLM-as-judge, no subjective evaluation:
Exact Match
Perfect string matching for precise answers
Contains
Check for required keywords or phrases
Regex
Pattern matching for structured outputs
Numeric
Tolerance-based number comparison
JSON Schema
Validate structured output against a schema
Multi-Label
Match multiple expected labels or categories
Plus 12 more modes including multi-label, ordered list, boolean, code execution, and pipeline variables for multi-step reasoning.
"Static benchmarks tell you which model is generally smart. Custom benchmarks tell you which model is smart at YOUR job. That's the only benchmark that matters for production."
What Makes This LLM Benchmark Different
LLM Benchmarking FAQ
What is an LLM benchmark?
An LLM benchmark is a structured test that evaluates language model performance on specific tasks. Generic benchmarks (MMLU, HumanEval) test standardized skills. Custom benchmarks (like OpenMark) test models on YOUR actual prompts and use cases.
How long does a benchmark take?
A typical benchmark with 8-10 models completes in 2-5 minutes. Results stream in real-time as each model responds. Faster models finish first.
Can I benchmark reasoning models like o3 and DeepSeek Reasoner?
Yes. OpenMark supports reasoning models and handles extended thinking time. Timeout profiles automatically adjust for slower models.
Can you run the benchmark for me?
Yes. The audit service ($299–$499) covers one recurring task across 10–20 models in 48 hours. Optional retainer at $500–$1,000/month for ongoing re-runs as new models ship. Best-fit for tasks with measurable outputs (classification, extraction, RAG grading, routing, moderation). Details on the audit page →
Why Teams Use OpenMark AI
No provider accounts required. OpenMark AI handles every API call via credits — just describe your task and run.
No Python SDK, no CLI, no notebook. Works for PMs, founders, and teams that don't want to spin up an eval pipeline.
Guided task builder, select models, run, results. No environment setup, no SDK, no configuration files.
Compare models from every major provider in a single benchmark run. Not 4, not "the big 3" — over 100.
Don't want to design the test yourself? Have us run it for you.
If reading this convinced you that custom benchmarking matters but you don't have a week to design one — we run it for you. Send us your task, we benchmark it across all relevant models (up to 30+) and send back a synthesized report with the recommended primary, fallbacks, cost-at-volume, and re-test triggers. From $299, 48-hour turnaround, no call required.
Benchmark LLMs on YOUR Task
100+ models. Deterministic scoring. Real costs.
Free tier — no credit card required.