LLM Leaderboard?
Build Your Own.
Generic leaderboards rank models on standardized tests. But your production task isn't standardized. Create a personal AI model leaderboard that ranks 100+ models on YOUR actual use case.
The Problem with LLM Leaderboards
LMSYS Chatbot Arena, Open LLM Leaderboard, MMLU rankings — they all suffer from the same problems:
Benchmark Contamination
Models may have trained on test data. A model scoring 92% on MMLU might score 65% on a novel, unseen task — like YOUR use case.
No Cost Data
Leaderboards rank by accuracy alone. A model that's 3% better but costs 50x more isn't the "best" for production workloads.
Generic Tasks
MMLU tests general knowledge. HumanEval tests Python. Your customer support, legal review, or data extraction pipeline isn't tested anywhere.
Subjective Voting
Arena-style leaderboards use human voting — subjective, noisy, and biased toward verbose/confident-sounding responses.
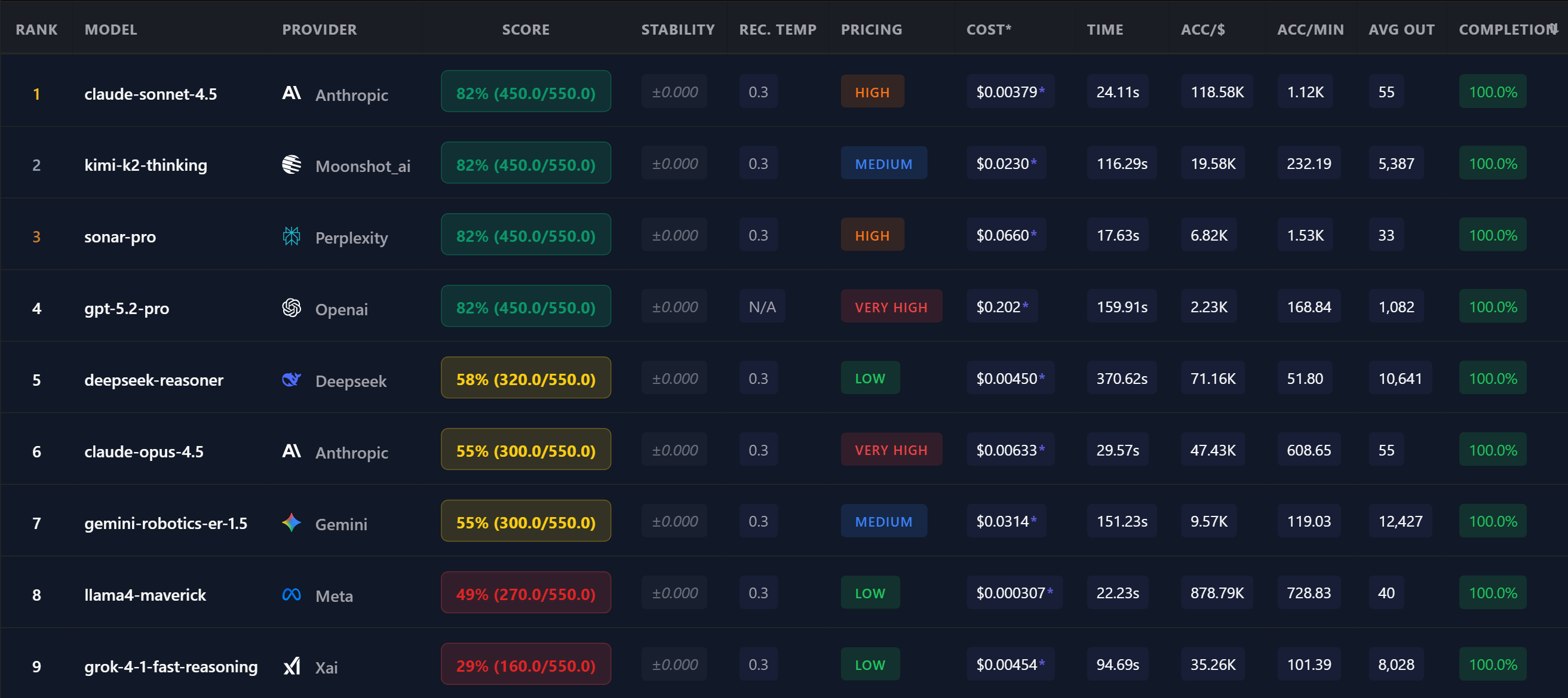
A real OpenMark leaderboard — YOUR task, YOUR rankings, YOUR data.
Your Custom LLM Leaderboard
OpenMark lets you create a leaderboard that matters — one based on YOUR actual prompts and use cases:
Leaderboard You Can Sort
Unlike static leaderboards, OpenMark's results table is interactive. Sort by any column to find the model that fits your priority:
| Rank | Model | Score | Cost | Acc/$ | Speed |
|---|---|---|---|---|---|
| 1 | claude-sonnet-4.5 Anthropic | 82% | $0.0038 | 118.5K | 24s |
| 2 | gpt-4o OpenAI | 78% | $0.0045 | 95.2K | 18s |
| 3 | deepseek-v3 DeepSeek | 75% | $0.0003 | 878.8K | 22s |
| 4 | gemini-2.5-flash | 73% | $0.0005 | 450.1K | 15s |
↑ Example data. YOUR leaderboard will reflect YOUR task's results.
"We replaced our weekly leaderboard check with a monthly OpenMark benchmark on our actual production prompts. We caught a model regression that leaderboards missed — our production pipeline would have broken."
FAQ
How is this different from the Chatbot Arena leaderboard?
Chatbot Arena ranks by human voting on random conversations — subjective and generic. OpenMark ranks by deterministic scoring on YOUR actual prompts, with cost and speed data included.
Can I compare my rankings over time?
Yes. Run the same benchmark monthly to track model improvements, regressions, and pricing changes. Your benchmark history is saved for comparison.
Does this replace standard benchmarks?
Not entirely. Standard benchmarks are useful for general capability assessment. But for production decisions, you need a leaderboard based on YOUR specific task. Learn more about custom benchmarking →
Can you run the benchmark for me?
Yes. The audit service ($299–$499) covers one recurring task across 10–20 models in 48 hours. Optional retainer at $500–$1,000/month for ongoing re-runs as new models ship. Best-fit for tasks with measurable outputs (classification, extraction, RAG grading, routing, moderation). Details on the audit page →
Why Teams Use OpenMark AI
No provider accounts required. OpenMark AI handles every API call via credits — just describe your task and run.
No Python SDK, no CLI, no notebook. Works for PMs, founders, and teams that don't want to spin up an eval pipeline.
Guided task builder, select models, run, results. No environment setup, no SDK, no configuration files.
Compare models from every major provider in a single benchmark run. Not 4, not "the big 3" — over 100.
Don't want to design the test yourself? Have us run it for you.
If you're researching which model to ship and want a definitive answer for your task instead of more reading — we run the eval for you. Send us your task, we benchmark it across all relevant models (up to 30+) and send back a synthesized report with the recommended primary, fallbacks, cost-at-volume, and re-test triggers. From $299, 48-hour turnaround, no call required.
Build Your Own LLM Leaderboard
Rank 100+ models on YOUR task. Real data, not generic scores.
Free tier — no credit card required.