AI Testing Tool
for Developers
Before you ship an LLM-powered feature, you need to know: which model is accurate, reliable, and cost-effective for YOUR use case? OpenMark is the testing tool that answers that.
Why You Need an AI Testing Tool
You wouldn't ship code without tests. Why ship an LLM integration without testing the model?
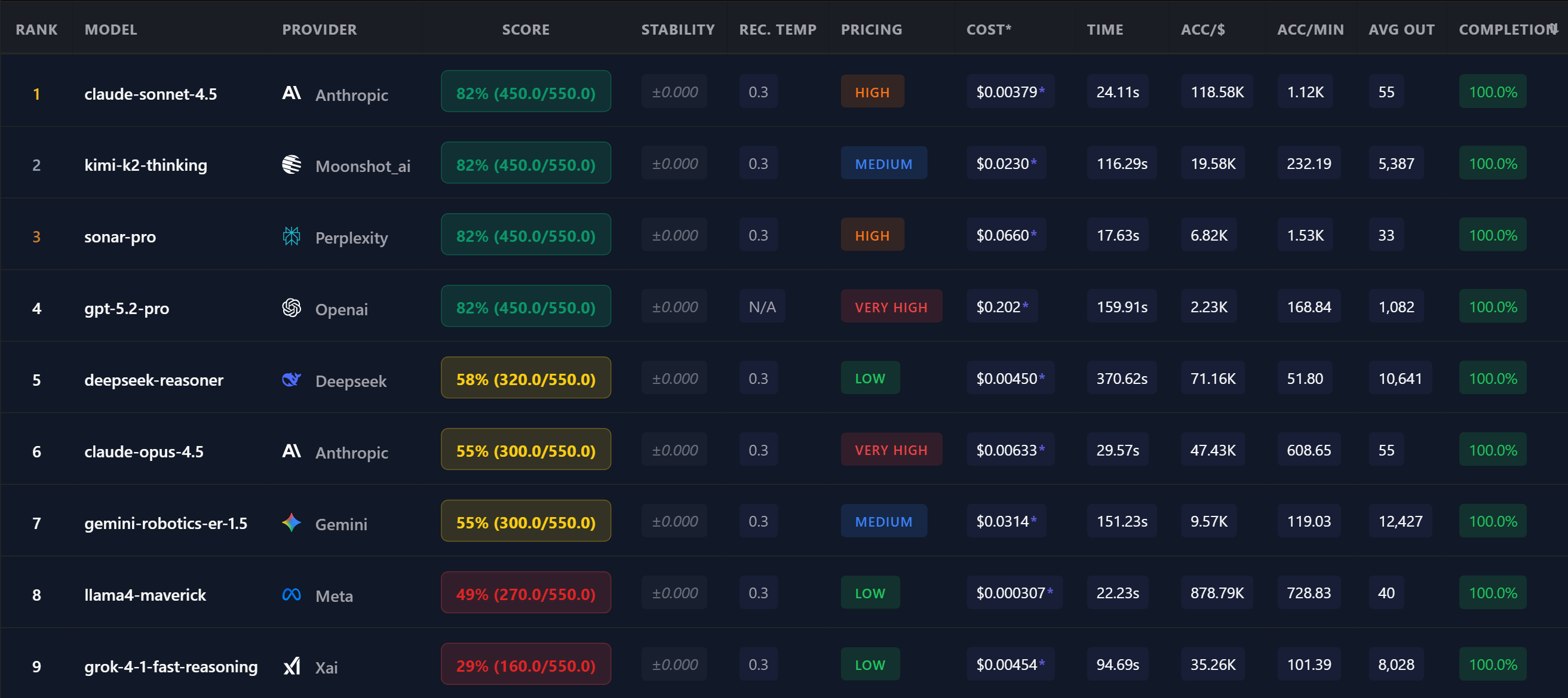
Model Selection
100+ models to choose from. Which one works best for your feature? Test before committing to a model and provider.
Regression Detection
Models get updated. A model that worked last month might degrade. Regular benchmarks catch regressions before your users do.
Cost Optimization
You might be paying 10x too much. A cheaper model might match your accuracy needs. Only testing reveals this.
Production Confidence
Deterministic scoring proves a model works for your task. No guessing, no vibes — just data.
How OpenMark Works as an AI Testing Tool
OpenMark is built for developers who need to evaluate LLMs quickly and reliably:
Testing Scenarios
OpenMark covers the full spectrum of AI evaluation needs:
🏗️ Model Selection
Testing 5-20 models before building a feature
🔄 Monthly Regression
Re-running benchmarks to catch model updates
💰 Cost Audit
Finding cheaper models that maintain quality
🆕 New Model Eval
Testing a newly released model on existing tasks
🌡️ Temperature Tuning
Finding optimal settings for each model
📋 Compliance Check
Verifying output format and content rules
"We used to spend 2 days manually testing models with spreadsheets. Now we run an OpenMark benchmark in 5 minutes and get better data. It's become part of our CI/CD mindset for AI features."
FAQ
What makes this different from manually testing in a playground?
Playgrounds test one model, one prompt at a time with no scoring. OpenMark tests 20+ models simultaneously with deterministic scoring, cost tracking, and stability metrics.
Do I need to write code?
No. Describe your test in plain language and OpenMark generates the benchmark automatically. For power users, you can write structured YAML for precise control.
Can I use this for LLM evaluation in production?
OpenMark is designed for pre-production evaluation and ongoing model monitoring. Run benchmarks before deploying and monthly to catch regressions. Learn more →
Can you run the benchmark for me?
Yes. The audit service ($299–$499) covers one recurring task across 10–20 models in 48 hours. Optional retainer at $500–$1,000/month for ongoing re-runs as new models ship. Best-fit for tasks with measurable outputs (classification, extraction, RAG grading, routing, moderation). Details on the audit page →
Why Teams Use OpenMark AI
No provider accounts required. OpenMark AI handles every API call via credits — just describe your task and run.
No Python SDK, no CLI, no notebook. Works for PMs, founders, and teams that don't want to spin up an eval pipeline.
Guided task builder, select models, run, results. No environment setup, no SDK, no configuration files.
Compare models from every major provider in a single benchmark run. Not 4, not "the big 3" — over 100.
Don't want to design the test yourself? Have us run it for you.
If reading this convinced you that custom benchmarking matters but you don't have a week to design one — we run it for you. Send us your task, we benchmark it across all relevant models (up to 30+) and send back a synthesized report with the recommended primary, fallbacks, cost-at-volume, and re-test triggers. From $299, 48-hour turnaround, no call required.
Test AI Models Before Production
100+ models. Deterministic scoring. Real costs.
Free tier — no credit card required.