Best AI for Classification
in 2026
Top 25 AI models benchmarked on subtle text classification — sentiment irony, intent detection, topic overlap, and spam filtering. The cheapest model tied for first. One popular model scored 0%.
What This Benchmark Tests (and Does Not Test)
All models tested with default API configurations. Exact_match scoring means the model must return only the label — any extra text causes a miss.
Benchmark Results
Key Findings
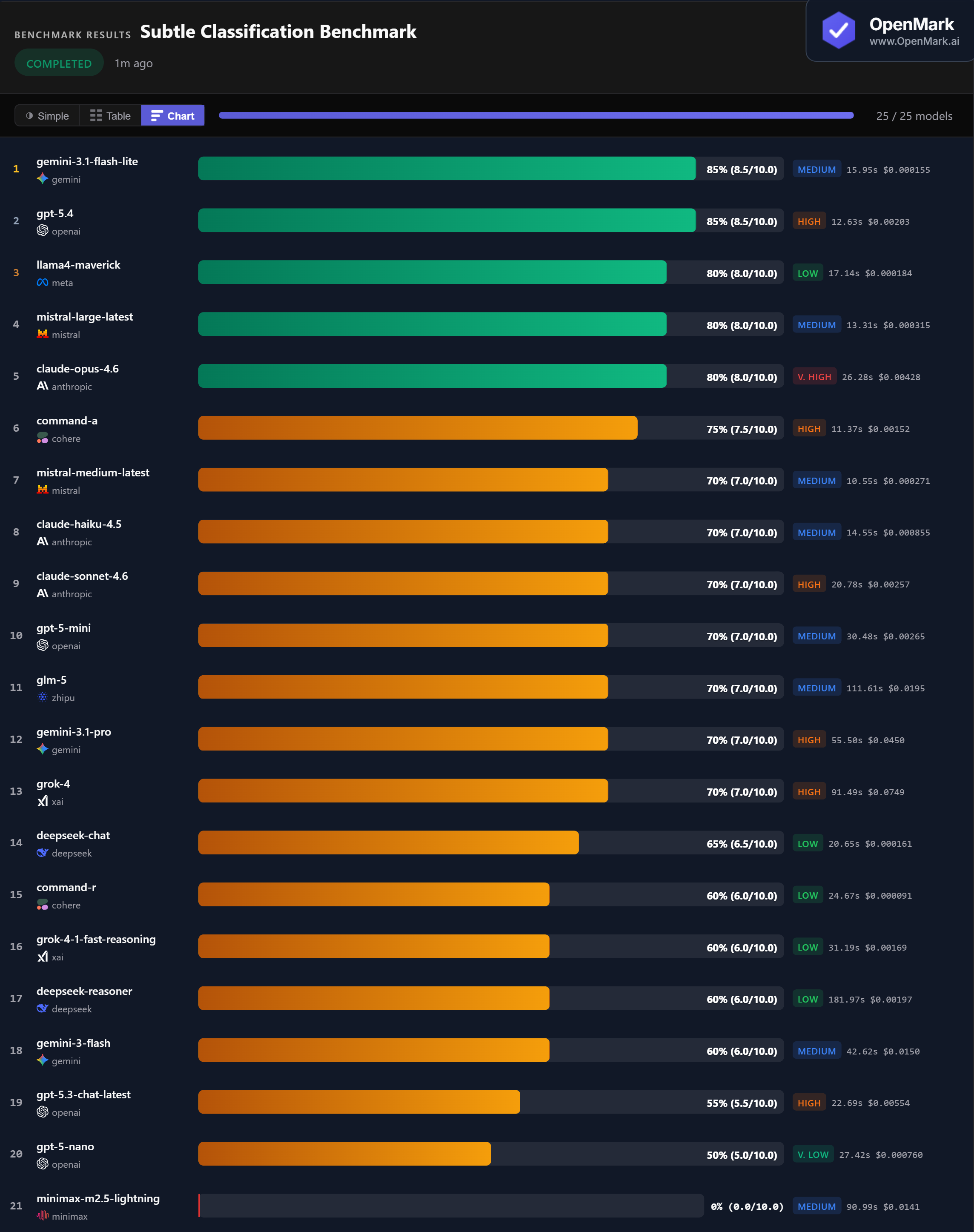
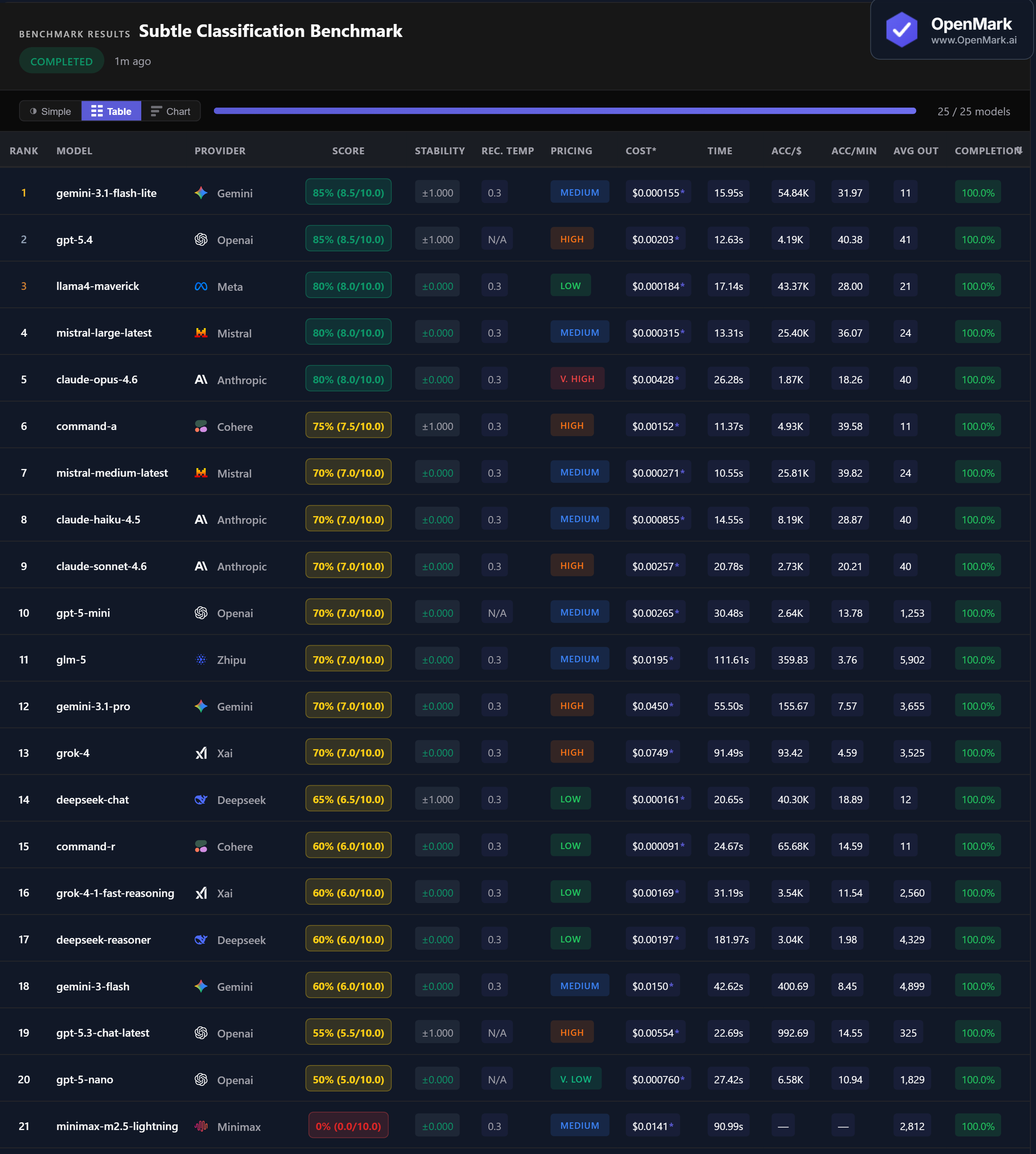
🏆 Accuracy: Gemini Flash Lite Ties GPT-5.4 at 85%
Gemini 3.1 Flash Lite and GPT-5.4 co-lead at 85% (8.5/10.0). Flash Lite costs $0.000155/run (Medium tier) while GPT-5.4 costs $0.00203/run (High tier) — a 13x price difference for the same accuracy. Three models follow at 80%: Llama4 Maverick, Mistral Large, and Claude Opus 4.6. Seven models cluster at exactly 70%.
💰 Cost Efficiency: Classification Is Nearly Free with the Right Model
Gemini Flash Lite scored 85% at $0.000155/run (54,839 Acc/$) — the co-winner is also the second cheapest model tested. Llama4 Maverick scored 80% at $0.000184/run (43,375 Acc/$). Mistral Large scored 80% at $0.000315/run. All three cost less than a tenth of a cent per classification and outperform models 100x their price.
⚡ Speed: GPT-5.4 Is the Fastest Top Scorer
GPT-5.4 responded in 12.63s with 85% accuracy — the fastest model in the top tier. Mistral Medium was overall fastest at 10.55s (70%). For the 80% tier, Mistral Large responded in 13.31s. Classification tasks produce minimal output (single labels), so speed differences reflect model latency rather than generation time.
📉 Minimax Scores 0% Despite 100% Completion
Minimax M2.5 Lightning scored 0% despite completing all tests with 100% completion rate. It likely produced verbose responses instead of single-word labels, causing exact_match to reject every answer. A model that excels at generating rich text can fail completely when the task requires a single label. Task format matters as much as model capability.
Why These Results May Surprise You
Gemini's cheapest model tying with GPT's flagship — while another model scores 0% despite completing every test — reveals fundamental truths about model capabilities:
This benchmark is the strongest evidence yet that there is no universally "best" model. A model's ranking changes dramatically based on what you ask it to do and how you score the output.
⚖️ Generic Benchmarks vs. Custom Benchmarks
These results are a directional signal, not a universal classification ranking. This benchmark tests 10 deliberately subtle classification tasks with exact_match scoring. Your classification needs might involve different label sets, multi-label scenarios, domain-specific categories, or production requirements where throughput and latency matter more than accuracy on edge cases.
The fact that Minimax scored 0% on classification despite being a capable model on other task types proves that no single model dominates all tasks. Gemini Flash Lite's co-win at $0.000155/run also shows that the most expensive model is rarely the best choice for structured output tasks.
These results are valid for this task design and scoring setup. Change the task, constraints, or scoring, and rankings can change — which is exactly why custom benchmarking matters.
Frequently Asked Questions
Which AI model is best for text classification in 2026?
On our subtle classification benchmark, Gemini 3.1 Flash Lite and GPT-5.4 tied at 85%. Flash Lite is dramatically cheaper ($0.000155 vs $0.00203/run). Three models scored 80%: Llama4 Maverick, Mistral Large, and Claude Opus 4.6. Run your own benchmark to test on your labels.
Is Claude or GPT better for classification?
GPT-5.4 scored 85% while Claude's best was Opus at 80%. Claude Sonnet and Haiku both scored 70%. Notably, Claude Opus (Very High tier) performed well on this structured-output task — suggesting Claude handles label-constrained tasks better than open-ended generation.
What is the cheapest AI for classification?
Gemini 3.1 Flash Lite co-won at 85% for just $0.000155/run. Llama4 Maverick scored 80% at $0.000184/run. Both cost less than a hundredth of a cent per classification.
How do you benchmark AI classification?
OpenMark uses deterministic exact_match scoring (case-insensitive). Each test requires a single-label output. Tasks are deliberately nuanced — ironic sentiment, backhanded compliments, domain-overlapping topics, and sophisticated spam. Results are 100% reproducible. Try it yourself for free.
Can AI detect sarcasm and irony in text?
To varying degrees. Top models (85%) handled ironic statements and backhanded compliments well, but many scored 70% or below, often misclassifying subtle sentiment. Only 2 of 21 completed models scored above 80% on these nuanced tasks.
Can OpenMark just do this for me?
Yes — for classification, the done-for-you audit is from $299 with 48-hour turnaround. Send your task definition, sample inputs, and pass/fail criteria; we benchmark it across all relevant models (up to 30+) and return a report with the recommended primary, fallbacks, and cost projections at your volume. See the audit service →
Why Teams Use OpenMark AI
You define the evaluation in your words, for your use case. Not MMLU, not HumanEval — your actual prompts, your actual data.
Multiple runs per model with variance tracking. A model that scores 90 once and 60 the next isn't the same as one that scores 85 every time.
See which model is cheapest for your task — scored against quality, not just raw price-per-token.
No accounts with OpenAI, Anthropic, or Google required. OpenMark AI handles every API call — just describe your task and run.
Don't want to design the test yourself? Have us run it for you.
If you don't want to design the classification test yourself or maintain it as new models ship — we run it for you on your data. Send us your task, we benchmark it across all relevant models (up to 30+) and send back a synthesized report with the recommended primary, fallbacks, cost-at-volume, and re-test triggers. From $299, 48-hour turnaround, no call required.
Benchmark AI Models on Your Classification Tasks
Test which model handles YOUR labels, edge cases, and categories best.
Build custom benchmarks for any task — text, code, structured output, classification, images, and more.
50 free credits — no API keys, no setup.