Best AI for Translation
in 2026
Top 25 AI models benchmarked on translation across 6 languages — short phrases, domain terminology, and formality registers. Scores were remarkably tight across the field.
What This Benchmark Tests (and Does Not Test)
All models tested with default API configurations. This benchmark measures keyword-level translation accuracy, not subjective fluency or naturalness.
Benchmark Results
Key Findings
🏆 Accuracy: Minimax Leads Again, but the Field Is Tight
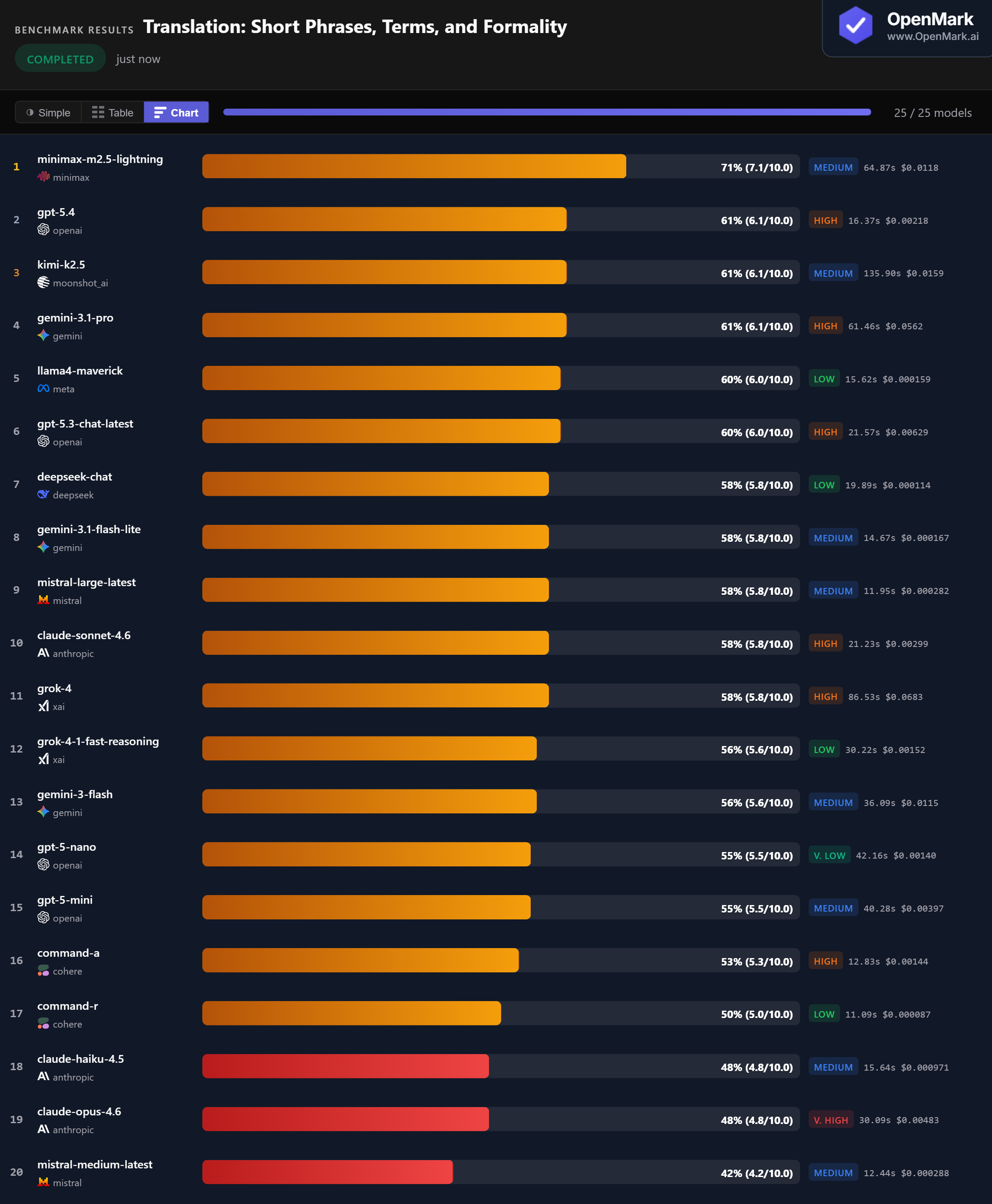
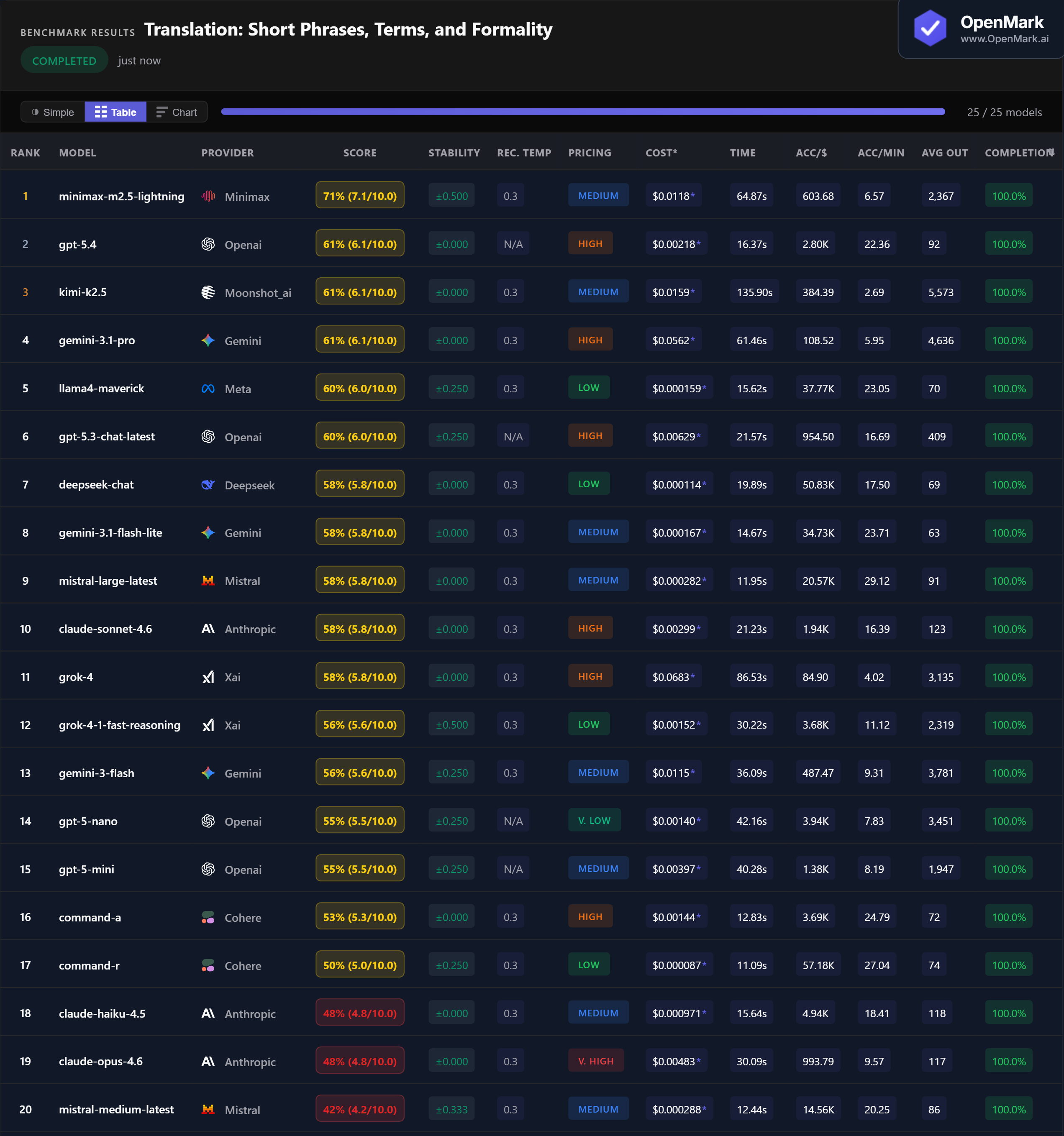
Minimax M2.5 Lightning leads at 71% (7.1/10.0), but the gap to the pack is narrow. Three models — GPT-5.4, Kimi K2.5, and Gemini 3.1 Pro — tie at 61%. Five models cluster at exactly 58%. Translation scores are compressed: only 29 points separate first from last among completed models.
💰 Cost Efficiency: Budget Models Translate Nearly as Well
DeepSeek Chat scored 58% at $0.000114/run (50,833 Acc/$) — matching Claude Sonnet, Mistral Large, and Grok-4 at a fraction of the cost. Llama4 Maverick scored 60% at $0.000159/run, just 1 point below the 61% tier. Grok-4 scored the same 58% as DeepSeek Chat but cost 599x more ($0.0683/run).
⚡ Speed: Mistral Large Is the Fast Translator
Mistral Large Latest responded in 11.95s with 58% accuracy — the best speed-to-accuracy ratio in the test. Command-R was fastest at 11.09s (50%). GPT-5.4 hit 61% in just 16.37s — the fastest model in the top tier. The winner Minimax took 64.87s, and Kimi K2.5 was slowest among completed models at 135.90s.
📉 Claude Struggles with Translation Tasks
Claude Opus 4.6 and Haiku 4.5 both scored 48% — the most expensive and cheapest Claude models tied at the bottom. Claude Sonnet 4.6 scored 58% but matched budget models like DeepSeek Chat ($0.000114) and Gemini Flash Lite ($0.000167). No Claude model cracked the top 5 on translation.
Why These Results May Surprise You
Translation scores are remarkably tight — the range is only 42% to 71% among completed models. Here's why:
Translation is inherently harder to score deterministically than math or extraction tasks. A model can produce a perfectly correct translation that doesn't match any expected variant. Keep this in mind when interpreting scores.
⚖️ Generic Benchmarks vs. Custom Benchmarks
These results are a directional signal, not a universal translation ranking. This benchmark tests short phrases across 6 languages with domain-specific terminology. Your translation needs might involve full documents, rare language pairs, technical manuals, or creative content where naturalness matters more than keyword accuracy.
The tight score clustering (58% for five different models from five providers) suggests that for short-phrase translation, most modern models perform similarly. The differences become meaningful when you factor in cost (DeepSeek at $0.000114 vs Grok-4 at $0.0683 for the same score) and speed (Mistral at 12s vs Kimi at 136s).
These results are valid for this task design and scoring setup. Change the task, constraints, or scoring, and rankings can change — which is exactly why custom benchmarking matters.
Frequently Asked Questions
Which AI model is best for translation in 2026?
On our multi-language translation benchmark, Minimax M2.5 Lightning scored highest at 71%, followed by GPT-5.4, Kimi K2.5, and Gemini 3.1 Pro tied at 61%. But scores are tight — 5 models scored 58%. The best model depends on your language pairs and domain. Run your own benchmark to find out.
Is Claude or GPT better for translation?
On this benchmark, GPT significantly outperformed Claude. GPT-5.4 scored 61% while Claude Sonnet 4.6 scored 58%, and both Claude Opus 4.6 and Haiku 4.5 scored 48%. Claude Opus — the priciest Claude model — tied with the cheapest Claude model (Haiku).
What is the cheapest AI for translation?
Command-R scored 50% at $0.000087/run. For better accuracy, DeepSeek Chat scored 58% at $0.000114/run and Llama4 Maverick scored 60% at $0.000159/run. All three are in the Low pricing tier — hundreds of times cheaper than premium models with similar scores.
How do you benchmark AI translation?
OpenMark uses deterministic scoring — no LLM-as-judge. Translation tasks use contains_all for required key terms and contains_any for acceptable translation variants. This measures keyword-level accuracy, not subjective fluency. Results are 100% reproducible. Try it yourself for free.
Which languages did this benchmark test?
English, Spanish, French, German, Japanese, and Simplified Chinese — 6 languages across 10 translation pairs. Tasks included medical terminology (German), legal terminology (French), business terminology (Chinese), and formal/informal register switching.
Can OpenMark just do this for me?
Yes — for translation, the done-for-you audit is from $299 with 48-hour turnaround. Send your task definition, sample inputs, and pass/fail criteria; we benchmark it across all relevant models (up to 30+) and return a report with the recommended primary, fallbacks, and cost projections at your volume. See the audit service →
Why Teams Use OpenMark AI
You define the evaluation in your words, for your use case. Not MMLU, not HumanEval — your actual prompts, your actual data.
Multiple runs per model with variance tracking. A model that scores 90 once and 60 the next isn't the same as one that scores 85 every time.
See which model is cheapest for your task — scored against quality, not just raw price-per-token.
No accounts with OpenAI, Anthropic, or Google required. OpenMark AI handles every API call — just describe your task and run.
Don't want to design the test yourself? Have us run it for you.
If you don't want to design the translation test yourself or maintain it as new models ship — we run it for you on your data. Send us your task, we benchmark it across all relevant models (up to 30+) and send back a synthesized report with the recommended primary, fallbacks, cost-at-volume, and re-test triggers. From $299, 48-hour turnaround, no call required.
Benchmark AI Models on Your Translation Tasks
Test which model handles YOUR language pairs and terminology best.
Build custom benchmarks for any task — text, code, structured output, classification, images, and more.
50 free credits — no API keys, no setup.