Best AI for Math
in 2026
Top 25 AI models benchmarked on complex math word problems — multi-step reasoning, algebra, and optimization. The cheapest model won. Here are the full results.
What This Benchmark Tests (and Does Not Test)
All models tested with default API configurations. Each prompt instructs the model to return only the numeric answer — no words, no units.
Benchmark Results
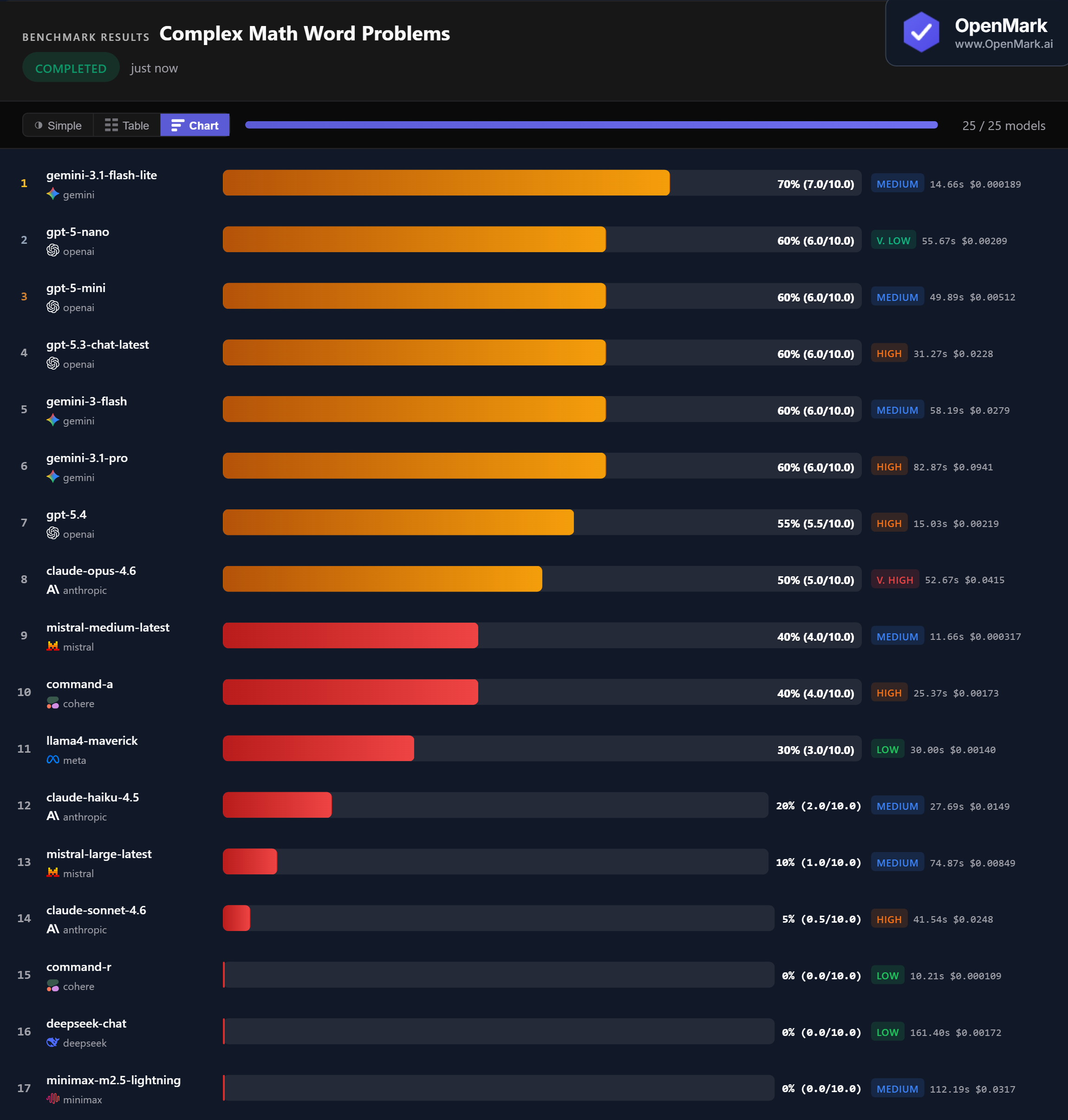
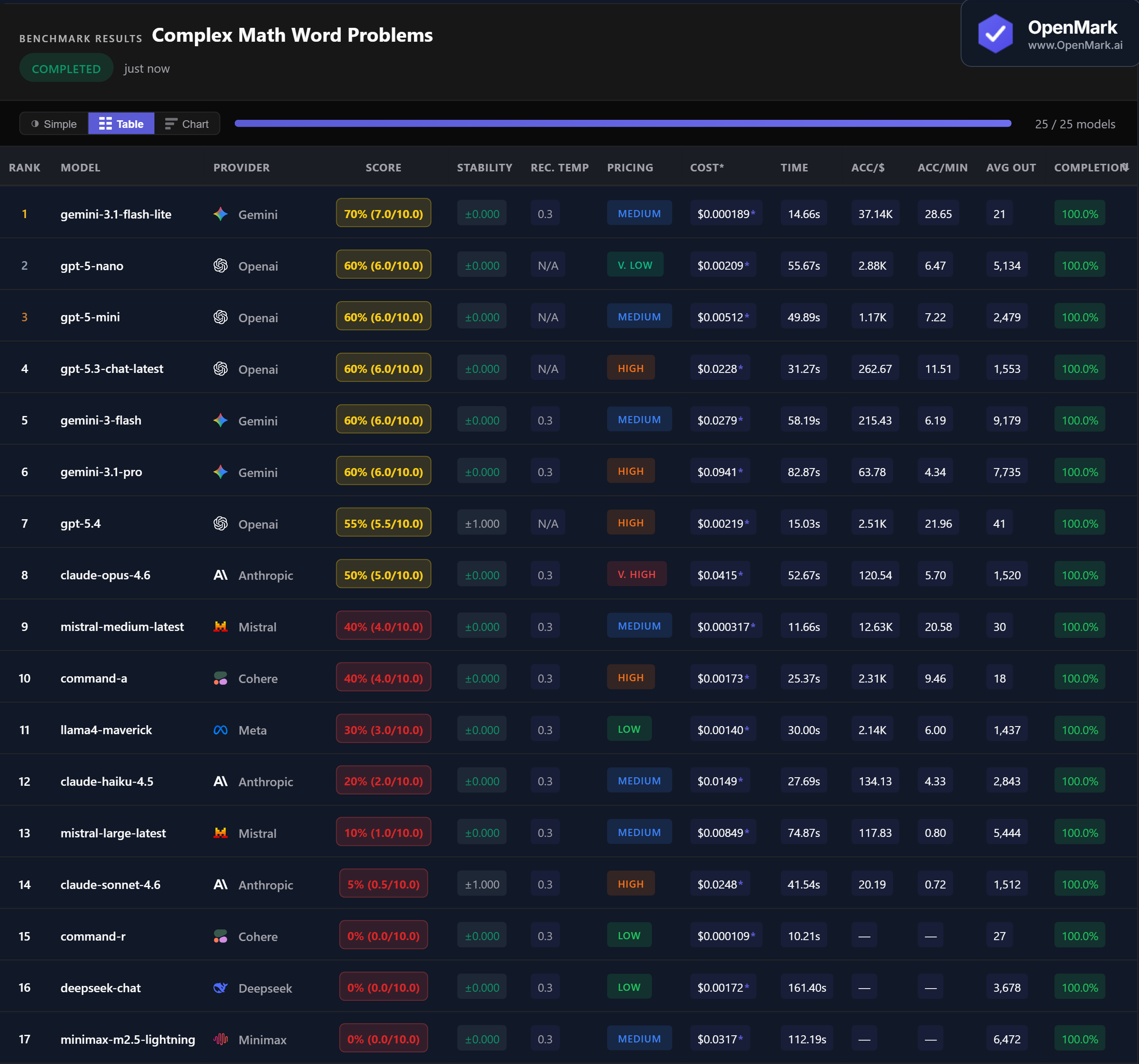
Key Findings
🏆 Accuracy: No Model Scores 100%
Gemini 3.1 Flash Lite leads at 70% (7.0/10.0) — the only model to break the 60% barrier across 10 math problems. Five models tied at 60%: GPT-5-nano, GPT-5-mini, GPT-5.3 Chat, Gemini 3 Flash, and Gemini 3.1 Pro. No model scored 100%, and three models scored 0%. This is a genuinely challenging benchmark.
💰 Cost Efficiency: The Cheapest Model Wins
Gemini 3.1 Flash Lite achieved the highest accuracy (70%) at the lowest cost ($0.000189/run) — an accuracy-per-dollar ratio of 37,135. For comparison, Gemini 3.1 Pro scored 10% less at nearly 500x the cost ($0.0941/run). Claude Opus 4.6, the priciest model at $0.0415/run, scored only 50%. On this benchmark, spending more bought you less.
⚡ Speed: Fast Models Hold Their Own
Mistral Medium Latest was the fastest scoring model at 11.66s (40% accuracy). The benchmark winner, Gemini 3.1 Flash Lite, responded in 14.66s — fast and accurate. The slowest model, Minimax M2.5 Lightning, took 112s and scored 0%. GPT-5.4 was notably fast at 15.03s but scored only 55%.
📉 Flagships Underperform on This Task
Claude Sonnet 4.6 scored just 5% ($0.0248/run, High tier). Claude Opus 4.6 scored 50% ($0.0415/run, Very High). GPT-5.4 scored 55%. Meanwhile, Gemini 3.1 Flash Lite scored 70% at a fraction of the cost. Expensive does not mean better — at least not for this type of deterministically-scored math task.
Why These Results May Surprise You
A $0.000189/run model beating a $0.0415/run model by 20 percentage points isn't a mistake — it's a feature of narrowly-scoped, deterministic benchmarks. Here's what's happening:
There is no universal winner — only task-conditional winners. That's the core insight, and it's exactly why custom benchmarking exists.
⚖️ Generic Benchmarks vs. Custom Benchmarks
These results are a directional signal, not a universal ranking. This benchmark tests specific problem types — multi-step word problems, algebraic rate problems, and optimization. Your actual math needs might involve financial calculations, physics equations, statistical analysis, or domain-specific modeling.
The fact that no model scored 100% — and that the cheapest model won — proves that model capability is task-dependent. The only way to know which model handles your math tasks best is to benchmark on your actual problems, with your data and your expected outputs.
These results are valid for this task design and scoring setup. Change the task, constraints, or scoring, and rankings can change — which is exactly why custom benchmarking matters.
Frequently Asked Questions
Which AI model is best for math in 2026?
On our complex math word problems benchmark, Gemini 3.1 Flash Lite scored highest at 70%, followed by five models tied at 60% (GPT-5-nano, GPT-5-mini, GPT-5.3 Chat, Gemini 3 Flash, and Gemini 3.1 Pro). But the best model for your use case depends on the type of math and your cost tolerance. Run your own benchmark to find out.
Are AI models good at solving math problems?
It depends on the problem type. On our benchmark, the best model scored 70% — not 100%. Simpler word problems are handled well by most models, but complex multi-step problems with increasing difficulty exposed significant gaps. Several frontier models scored below 60%, and some scored 0%.
What is the cheapest AI model for math?
Gemini 3.1 Flash Lite scored highest (70%) at just $0.000189/run — the cheapest AND most accurate model on this benchmark. Its accuracy-per-dollar ratio of 37,135 was far ahead of every other model. Mistral Medium Latest also performed well at 40% for $0.000317/run.
How do you benchmark AI models on math?
OpenMark uses deterministic scoring — no LLM-as-judge. Math tasks are scored using numeric extraction and exact match against known correct answers, so results are 100% reproducible. You can benchmark models on your own math problems for free.
Is GPT better than Claude at math?
On this benchmark, yes. GPT-5-nano and GPT-5-mini both scored 60%, while Claude Opus 4.6 scored 50% and Claude Sonnet 4.6 scored just 5%. But these results reflect this specific task and scoring setup. Different math problems or scoring methods could produce different rankings — which is why custom benchmarking matters.
Can OpenMark just do this for me?
Yes — for math, the done-for-you audit is from $299 with 48-hour turnaround. Send your task definition, sample inputs, and pass/fail criteria; we benchmark it across all relevant models (up to 30+) and return a report with the recommended primary, fallbacks, and cost projections at your volume. See the audit service →
Why Teams Use OpenMark AI
You define the evaluation in your words, for your use case. Not MMLU, not HumanEval — your actual prompts, your actual data.
Multiple runs per model with variance tracking. A model that scores 90 once and 60 the next isn't the same as one that scores 85 every time.
See which model is cheapest for your task — scored against quality, not just raw price-per-token.
No accounts with OpenAI, Anthropic, or Google required. OpenMark AI handles every API call — just describe your task and run.
Don't want to design the test yourself? Have us run it for you.
If you don't want to design the math test yourself or maintain it as new models ship — we run it for you on your data. Send us your task, we benchmark it across all relevant models (up to 30+) and send back a synthesized report with the recommended primary, fallbacks, cost-at-volume, and re-test triggers. From $299, 48-hour turnaround, no call required.
Benchmark AI Models on Your Math Tasks
Test which model solves YOUR math problems best.
Build custom benchmarks for any task — text, code, structured output, classification, images, and more.
50 free credits — no API keys, no setup.