Best AI for Writing
in 2026
Top 25 AI models benchmarked on constrained writing tasks — product descriptions, formal emails, tone rewrites, and brand taglines. An unexpected model won.
What This Benchmark Tests (and Does Not Test)
All models tested with default API configurations. This benchmark measures constraint-following, not subjective writing quality.
Benchmark Results

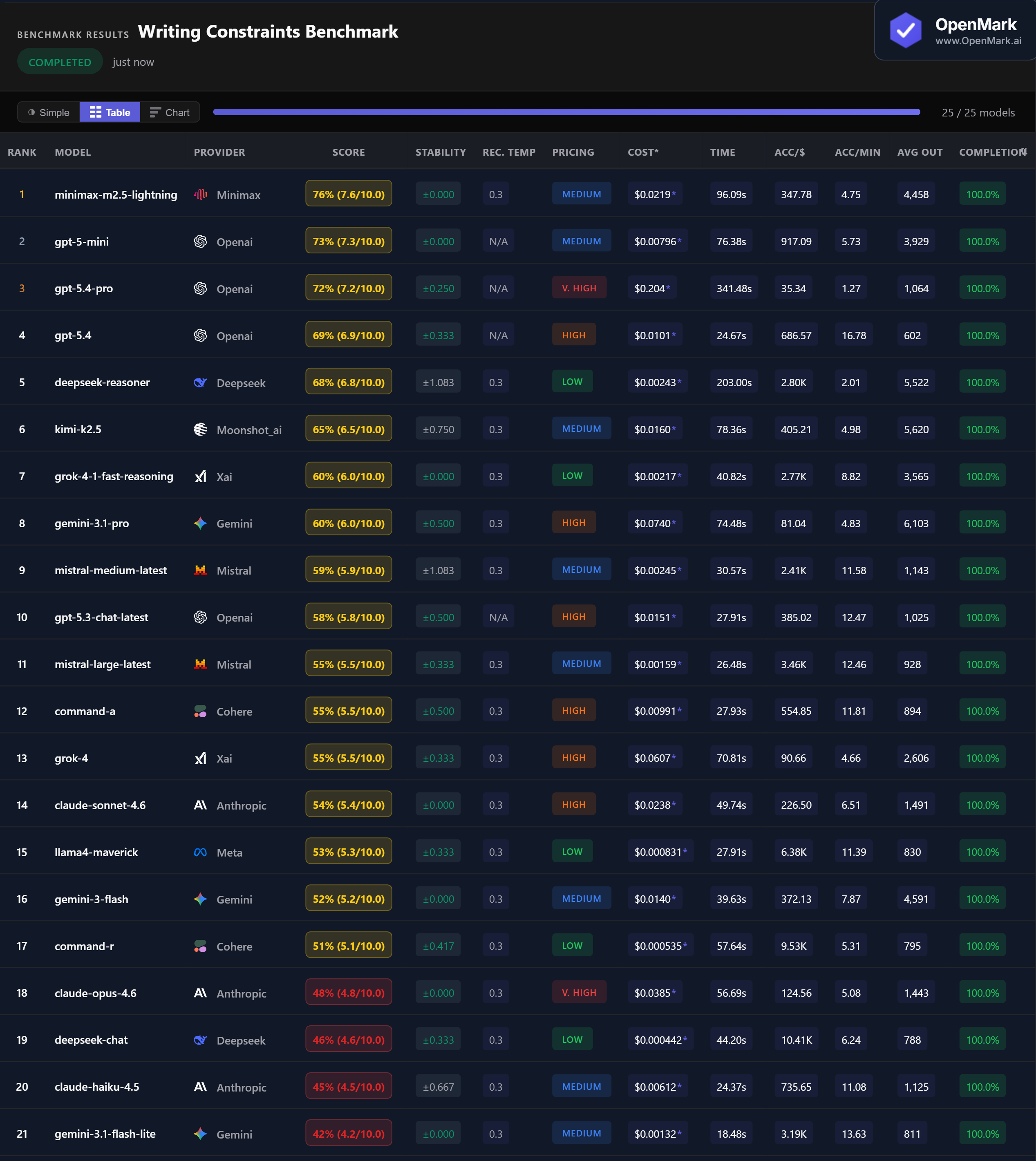
Key Findings
🏆 Accuracy: Minimax Takes the Lead
Minimax M2.5 Lightning leads at 76% (7.6/10.0) with perfect ±0.000 stability — the most consistent top scorer. GPT-5-mini follows at 73%, then GPT-5.4-Pro at 72%. The top 3 come from three different providers. No model scored above 76%, showing that constrained writing remains challenging even for frontier models.
💰 Cost Efficiency: GPT-5-mini Delivers the Best Value
GPT-5-mini scored 73% at $0.00796/run — nearly matching GPT-5.4-Pro (72%) at 1/26th the cost ($0.204/run). For budget-conscious users, DeepSeek Reasoner scored 68% at just $0.00243/run (Low tier). The cheapest model overall, DeepSeek Chat, scored 46% at $0.000442/run — an accuracy-per-dollar ratio of 10,411.
⚡ Speed: GPT-5.4 Is the Fast Performer
GPT-5.4 responded in 24.67s with 69% accuracy — the best speed-to-accuracy ratio. Gemini 3.1 Flash Lite was fastest at 18.48s but scored only 42%. The winner Minimax M2.5 Lightning took 96s, and GPT-5.4-Pro was slowest at 341s. For real-time writing assistance, GPT-5.4 or Mistral Large (26.48s, 55%) are the practical choices.
📉 Claude Underperforms on Constrained Writing
Claude Opus 4.6 scored just 48% ($0.0385/run, Very High tier) — lower than Llama4 Maverick (53%) which costs 46x less. Claude Sonnet 4.6 scored 54%, and Claude Haiku 4.5 scored 45%. All three Claude models landed in the bottom half. On constraint-following tasks with checklist scoring, Claude's verbose style works against it.
Why These Results May Surprise You
Minimax beating GPT-5.4-Pro by 4 points at 1/10th the cost defies expectations. But constrained writing benchmarks reward different skills than open-ended creative writing:
There is no universal winner — only task-conditional winners. A model that excels at following content checklists might not be the best for open-ended blog posts or creative fiction.
⚖️ Generic Benchmarks vs. Custom Benchmarks
These results are a directional signal, not a universal writing quality ranking. This benchmark tests specific constraint-following tasks — product descriptions with required features, emails with required elements, tone rewrites, and taglines. Your writing needs might involve blog posts, technical documentation, marketing copy, or creative fiction.
The fact that Minimax — a model few would pick as "best writer" — scored highest proves that model capability is deeply task-dependent. The only way to know which model handles your writing tasks best is to benchmark on your actual content requirements.
These results are valid for this task design and scoring setup. Change the task, constraints, or scoring, and rankings can change — which is exactly why custom benchmarking matters.
Frequently Asked Questions
Which AI model is best for writing in 2026?
On our constrained writing benchmark, Minimax M2.5 Lightning scored highest at 76%, followed by GPT-5-mini (73%) and GPT-5.4-Pro (72%). But the best model depends on your writing tasks. For open-ended creative writing, results may differ. Run your own benchmark to find out.
Is Claude or GPT better for writing?
On this benchmark, GPT significantly outperformed Claude. GPT-5-mini scored 73% while Claude Sonnet 4.6 scored 54% and Claude Opus 4.6 scored just 48%. However, this tests constraint-following with checklist scoring — open-ended creative writing might produce different rankings.
What is the cheapest AI for writing?
DeepSeek Chat scored 46% at just $0.000442/run. For better accuracy on a budget, DeepSeek Reasoner scored 68% at $0.00243/run, and GPT-5-mini scored 73% at $0.00796/run — the best value-for-accuracy in the test.
How do you benchmark AI writing quality?
OpenMark uses deterministic scoring — no LLM-as-judge. Writing tasks are scored using contains_all (must include required elements) and contains_any (must include at least one acceptable phrasing). This measures constraint-following, not subjective quality. Results are 100% reproducible. Try it yourself for free.
Can AI write product descriptions and emails?
Yes, most models produce coherent product descriptions and formal emails. But they vary widely in following specific constraints — including required features, maintaining tone, and hitting content requirements. Our benchmark showed scores from 42% to 76% on these exact tasks.
Why Teams Use OpenMark AI
You define the evaluation in your words, for your use case. Not MMLU, not HumanEval — your actual prompts, your actual data.
Multiple runs per model with variance tracking. A model that scores 90 once and 60 the next isn't the same as one that scores 85 every time.
See which model is cheapest for your task — scored against quality, not just raw price-per-token.
No accounts with OpenAI, Anthropic, or Google required. OpenMark AI handles every API call — just describe your task and run.
Benchmark AI Models on Your Writing Tasks
Test which model follows YOUR content requirements best.
Build custom benchmarks for any task — text, code, structured output, classification, images, and more.
50 free credits — no API keys, no setup.