Best AI for Summarization
in 2026
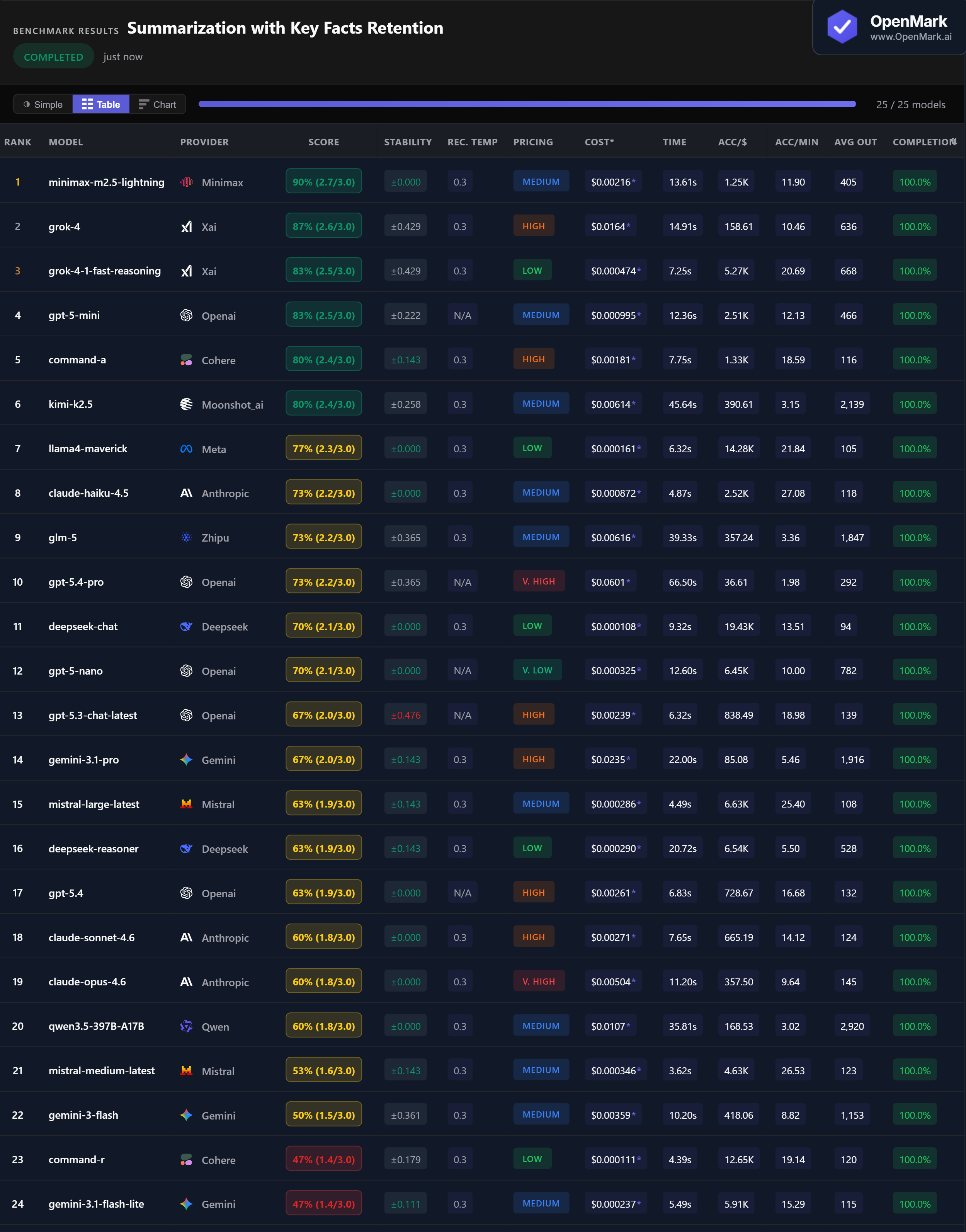
Top 25 AI models benchmarked on summarization with key facts retention — passage summarization, argument extraction, and bullet-point condensation. One model retained 90% of required facts.
What This Benchmark Tests (and Does Not Test)
All models tested with default API configurations. This benchmark measures fact retention in short summaries, not subjective summary quality.
Benchmark Results

Key Findings
🏆 Accuracy: Minimax Dominates at 90%
Minimax M2.5 Lightning leads at 90% (2.7/3.0) with perfect ±0.000 stability — retaining nearly all required key facts across every run. Grok-4 follows at 87%, then Grok-4-1 Fast Reasoning and GPT-5-mini tied at 83%. The top scorer comes from the least expected provider, while XAI and OpenAI fill the podium.
💰 Cost Efficiency: DeepSeek Chat — 70% at a Fraction of a Cent
DeepSeek Chat scored 70% at $0.000108/run — the highest accuracy-per-dollar ratio in the test (19,430 Acc/$). Llama4 Maverick scored 77% at $0.000161/run (14,279 Acc/$). For top accuracy on a budget, Grok-4-1 Fast Reasoning scored 83% at just $0.000474/run — 127x cheaper than GPT-5.4-Pro (73%).
⚡ Speed: Claude Haiku Is the Fast Fact-Retainer
Claude Haiku 4.5 responded in 4.87s with 73% accuracy — the best speed-to-accuracy ratio in the test. Mistral Medium was fastest overall at 3.62s but scored only 53%. Llama4 Maverick hit 77% in 6.32s. The winner Minimax took 13.61s, and GPT-5.4-Pro was slowest at 66.50s for a lower 73% score.
📉 Flagships Beaten by Their Own Cheaper Siblings
GPT-5-mini (83%) outperformed GPT-5.4-Pro (73%) at 1/60th the cost. Claude Haiku 4.5 (73%) beat both Claude Sonnet 4.6 (60%) and Claude Opus 4.6 (60%) — the cheapest Claude model outperformed the most expensive by 13 points. In summarization, bigger and pricier does not mean better at retaining facts.
Why These Results May Surprise You
Minimax scoring 90% on summarization while Claude Opus manages only 60% seems wrong — until you understand what's being measured:
A model that excels at retaining exact facts in short summaries might not be the best at producing executive summaries of 50-page documents. Task design determines rankings.
⚖️ Generic Benchmarks vs. Custom Benchmarks
These results are a directional signal, not a universal summarization ranking. This benchmark tests short-form fact retention across three specific task types — passage summarization, argument extraction, and bullet-point condensation. Your summarization needs might involve legal documents, medical records, financial reports, or meeting transcripts.
The fact that Minimax — a model most teams wouldn't consider for production summarization — scored 90% while Claude Opus scored 60% shows how sensitive rankings are to task design and scoring method. A contains_all scorer rewards literal fact retention; a human evaluator might rank these models very differently.
These results are valid for this task design and scoring setup. Change the task, constraints, or scoring, and rankings can change — which is exactly why custom benchmarking matters.
Frequently Asked Questions
Which AI model is best for summarization in 2026?
On our key facts retention benchmark, Minimax M2.5 Lightning scored highest at 90% with perfect stability, followed by Grok-4 (87%) and GPT-5-mini (83%). But the best model depends on your document types and what you need from summaries. Run your own benchmark to find out.
Is Claude or GPT better for summarization?
On this benchmark, GPT significantly outperformed Claude. GPT-5-mini scored 83% while Claude Haiku 4.5 scored 73%, and both Claude Sonnet 4.6 and Opus 4.6 scored just 60%. Notably, the cheapest Claude model (Haiku) outperformed both premium Claude models on fact retention.
What is the cheapest AI for summarization?
DeepSeek Chat scored 70% at just $0.000108/run — the cheapest option tested. Llama4 Maverick scored 77% at $0.000161/run. For the best balance of accuracy and cost, Grok-4-1 Fast Reasoning scored 83% at $0.000474/run (Low tier).
How do you benchmark AI summarization?
OpenMark uses deterministic scoring — no LLM-as-judge. Summarization tasks are scored using contains_all with partial credit, checking whether each summary retains specific key facts from the source text. This measures fact retention, not subjective quality. Results are 100% reproducible. Try it yourself for free.
Can AI accurately summarize documents?
Yes, but accuracy varies widely. Scores on our benchmark ranged from 47% to 90%. Even premium models missed key facts — Claude Opus retained just 60%. For production use, always test on your actual document types to understand fact loss rates.
Can OpenMark just do this for me?
Yes — for summarization, the done-for-you audit is from $299 with 48-hour turnaround. Send your task definition, sample inputs, and pass/fail criteria; we benchmark it across all relevant models (up to 30+) and return a report with the recommended primary, fallbacks, and cost projections at your volume. See the audit service →
Why Teams Use OpenMark AI
You define the evaluation in your words, for your use case. Not MMLU, not HumanEval — your actual prompts, your actual data.
Multiple runs per model with variance tracking. A model that scores 90 once and 60 the next isn't the same as one that scores 85 every time.
See which model is cheapest for your task — scored against quality, not just raw price-per-token.
No accounts with OpenAI, Anthropic, or Google required. OpenMark AI handles every API call — just describe your task and run.
Don't want to design the test yourself? Have us run it for you.
If you don't want to design the summarization test yourself or maintain it as new models ship — we run it for you on your data. Send us your task, we benchmark it across all relevant models (up to 30+) and send back a synthesized report with the recommended primary, fallbacks, cost-at-volume, and re-test triggers. From $299, 48-hour turnaround, no call required.
Benchmark AI Models on Your Summarization Tasks
Test which model retains the facts YOU need in summaries.
Build custom benchmarks for any task — text, code, structured output, classification, images, and more.
50 free credits — no API keys, no setup.