Best AI for Sentiment Analysis
in 2026
Top 20 AI models benchmarked on difficult sentiment analysis — sarcasm, irony, double negatives, and mixed signals across movie reviews, product feedback, and tweets. The cheapest model tied for first.
What This Benchmark Tests (and Does Not Test)
All models tested with default API configurations. Weighted scoring means sarcasm and ambiguity failures cost significantly more points than simpler misclassifications.
Benchmark Results
Key Findings
🏆 Accuracy: Three-Way Tie at 90% — Led by the Cheapest Model
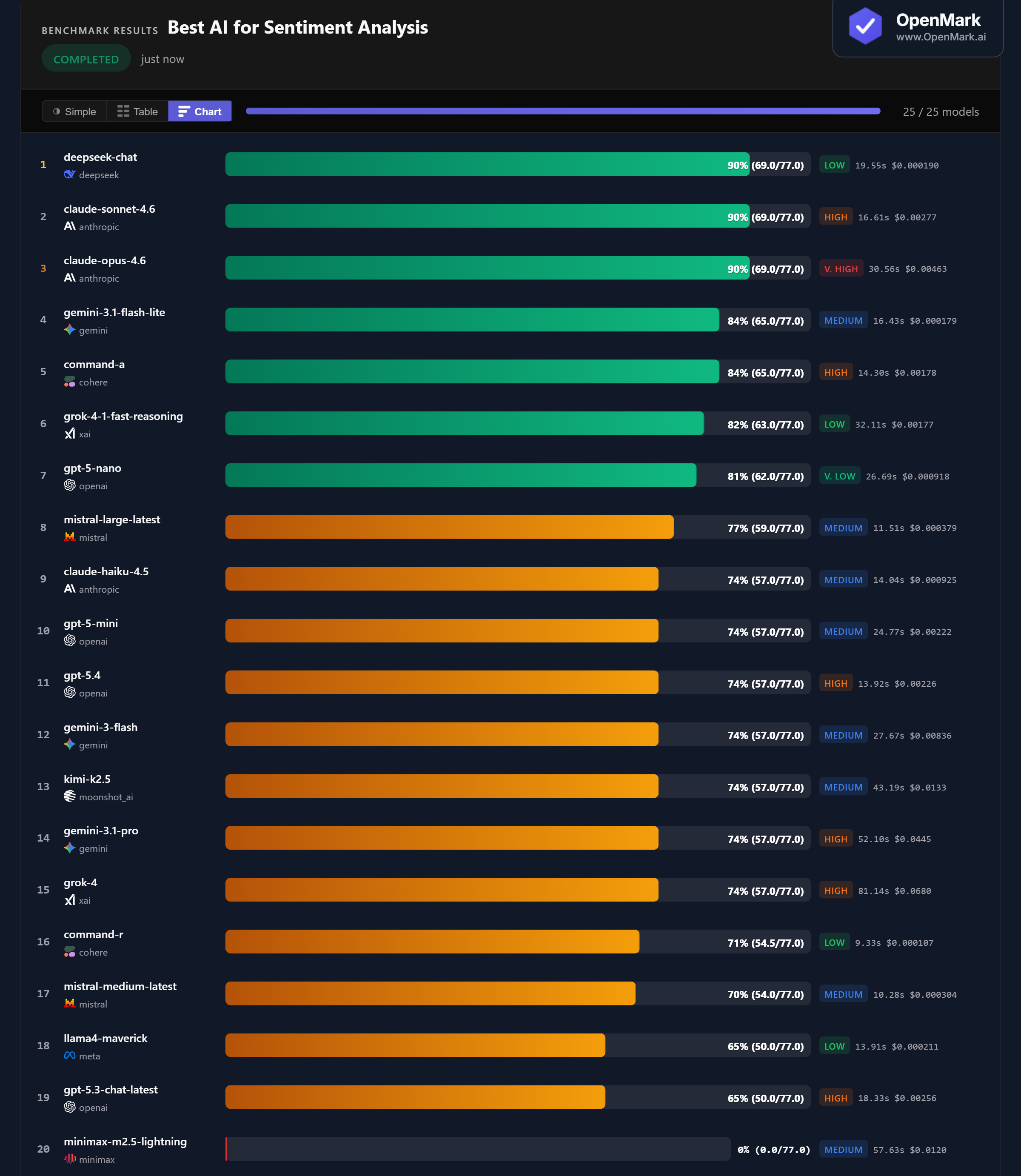
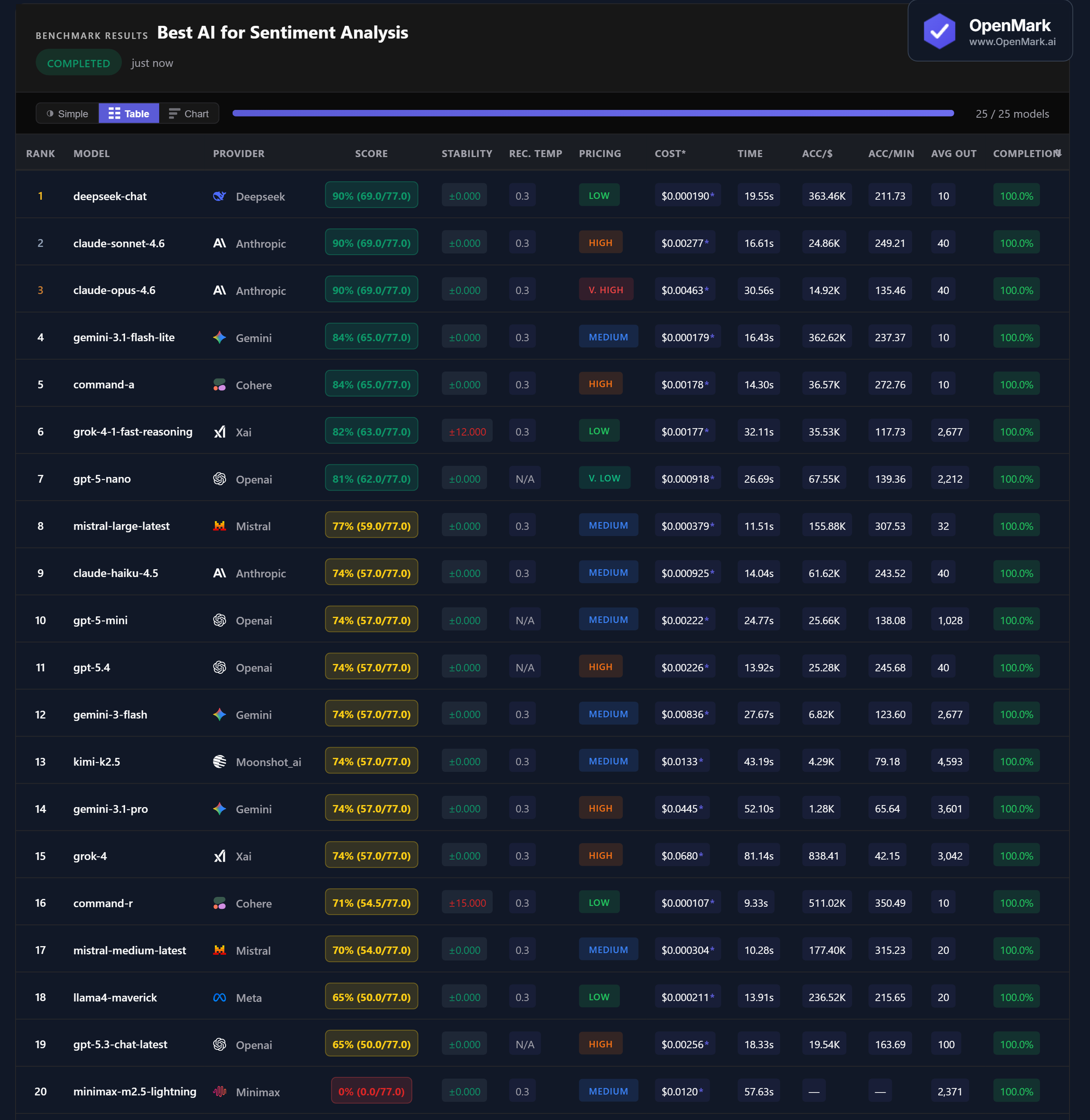
DeepSeek Chat, Claude Sonnet 4.6, and Claude Opus 4.6 all scored 90% (69.0/77.0). The cheapest model in the field (DeepSeek, Low tier) matched the most expensive (Claude Opus, Very High tier). No model scored above 90% — the hardest sarcasm and ambiguity tests tripped up every model. Gemini 3.1 Flash Lite and Command-A tied for 4th at 84%.
💰 Cost Efficiency: DeepSeek Delivers 90% for Near-Zero Cost
DeepSeek Chat scored 90% at $0.000190/run — accuracy-per-dollar of 363,464. Claude Sonnet matched the score but costs 14x more ($0.00277). Claude Opus matched it too — at 24x the cost ($0.00463). Gemini Flash Lite scored 84% at $0.000179/run (362,622 Acc/$), making it the best value for users who don't need the absolute top score.
⚡ Speed: Mistral and Command-R Are the Fastest Analyzers
Command-R responded in 9.33s (71% accuracy) and Mistral Medium Latest in 10.28s (70%). Among the top scorers, Claude Sonnet at 16.61s was the fastest 90% model. DeepSeek Chat took 19.55s — still fast for the top tier. The slowest in the field: Grok-4 at 81.14s for only 74%.
📉 Seven Models Cluster at Exactly 74% — The Sarcasm Wall
GPT-5 Mini, GPT-5.4, Gemini 3 Flash, Kimi K2.5, Gemini 3.1 Pro, Grok-4, and Claude Haiku 4.5 all scored exactly 74% (57.0/77.0). This clustering suggests a capability boundary: these models handle straightforward sentiment correctly but consistently fail on the highest-weighted sarcasm and ambiguity tests — which cost 12-15 points each.
Why These Results May Surprise You
A Low-tier model tying with a Very High-tier model at the top of the leaderboard is unusual. Here's what's happening:
Sentiment analysis — particularly sarcasm detection — is one of the few tasks where model price is genuinely uncorrelated with performance. A $0.000190 model can match a $0.00463 model because the skill being tested (pragmatic language understanding) doesn't scale linearly with parameters or training cost.
⚖️ Generic Benchmarks vs. Custom Benchmarks
These results are a directional signal, not a universal sentiment analysis ranking. This benchmark deliberately targets the hardest edge cases — sarcasm, irony, double negatives, mixed signals. A benchmark focused on straightforward product reviews would likely show much higher (and tighter) scores across all models.
The three-way tie at 90% — between a $0.000190 model and a $0.00463 model — is a striking example of why cost should never be your first filter. The 7-model cluster at 74% shows that most modern models handle basic sentiment well, but the differentiator is performance on edge cases that matter to your specific use case.
These results are valid for this task design and scoring setup. Change the task, constraints, or scoring, and rankings can change — which is exactly why custom benchmarking matters.
Frequently Asked Questions
Which AI model is best for sentiment analysis in 2026?
On our benchmark featuring sarcasm, irony, and ambiguous text, DeepSeek Chat, Claude Sonnet 4.6, and Claude Opus 4.6 all tied at 90%. DeepSeek achieved this at $0.000190/run — 24x cheaper than Claude Opus. The best model depends on your text types and edge cases. Run your own benchmark to find out.
Can AI detect sarcasm in text?
Yes, but not perfectly. The top models scored 90% on our heavily sarcastic benchmark — meaning even the best miss some sarcastic cues. Sarcasm is among the hardest sentiment tasks because positive surface words ("fantastic," "five stars") carry negative intent. Seven models hit a "sarcasm wall" at exactly 74%.
Is DeepSeek or Claude better for sentiment analysis?
They tied at 90%. DeepSeek Chat costs $0.000190/run versus Claude Sonnet's $0.00277 and Claude Opus's $0.00463. For identical accuracy, DeepSeek is 14-24x cheaper. Claude Haiku (the budget Claude model) scored lower at 74% — matching GPT-5.4 and seven other models at the sarcasm boundary.
What is the cheapest AI for sentiment analysis?
DeepSeek Chat scored 90% at $0.000190/run — the highest accuracy at the lowest cost. Gemini 3.1 Flash Lite scored 84% at $0.000179/run — technically cheaper per run but slightly less accurate. Both outperform premium models costing 10-100x more.
How does OpenMark benchmark sentiment analysis?
OpenMark uses deterministic exact_match scoring — no LLM-as-judge. Each model must return exactly "positive", "negative", or "neutral" for each text. Tests use weighted scoring (2-15 points) so harder tasks like sarcasm detection matter more than easy classifications. Results are 100% reproducible. Try it yourself for free.
Can OpenMark just do this for me?
Yes — for sentiment analysis, the done-for-you audit is from $299 with 48-hour turnaround. Send your task definition, sample inputs, and pass/fail criteria; we benchmark it across all relevant models (up to 30+) and return a report with the recommended primary, fallbacks, and cost projections at your volume. See the audit service →
Why Teams Use OpenMark AI
You define the evaluation in your words, for your use case. Not MMLU, not HumanEval — your actual prompts, your actual data.
Multiple runs per model with variance tracking. A model that scores 90 once and 60 the next isn't the same as one that scores 85 every time.
See which model is cheapest for your task — scored against quality, not just raw price-per-token.
No accounts with OpenAI, Anthropic, or Google required. OpenMark AI handles every API call — just describe your task and run.
Don't want to design the test yourself? Have us run it for you.
If you don't want to design the sentiment analysis test yourself or maintain it as new models ship — we run it for you on your data. Send us your task, we benchmark it across all relevant models (up to 30+) and send back a synthesized report with the recommended primary, fallbacks, cost-at-volume, and re-test triggers. From $299, 48-hour turnaround, no call required.
Benchmark AI Models on Your Sentiment Tasks
Test which model detects YOUR sarcasm, irony, and edge cases best.
Build custom benchmarks for any task — text, code, structured output, classification, images, and more.
50 free credits — no API keys, no setup.