Best AI for Logical Reasoning
in 2026
Top 14 AI models benchmarked on logical reasoning — syllogisms, deductive inference, constraint puzzles, and math reasoning with escalating difficulty. No model broke 70%.
What This Benchmark Tests (and Does Not Test)
All models tested with default API configurations. 11 of 25 models failed to complete all tests — reasoning tasks caused significantly more failures than any other benchmark category.
Benchmark Results
Key Findings
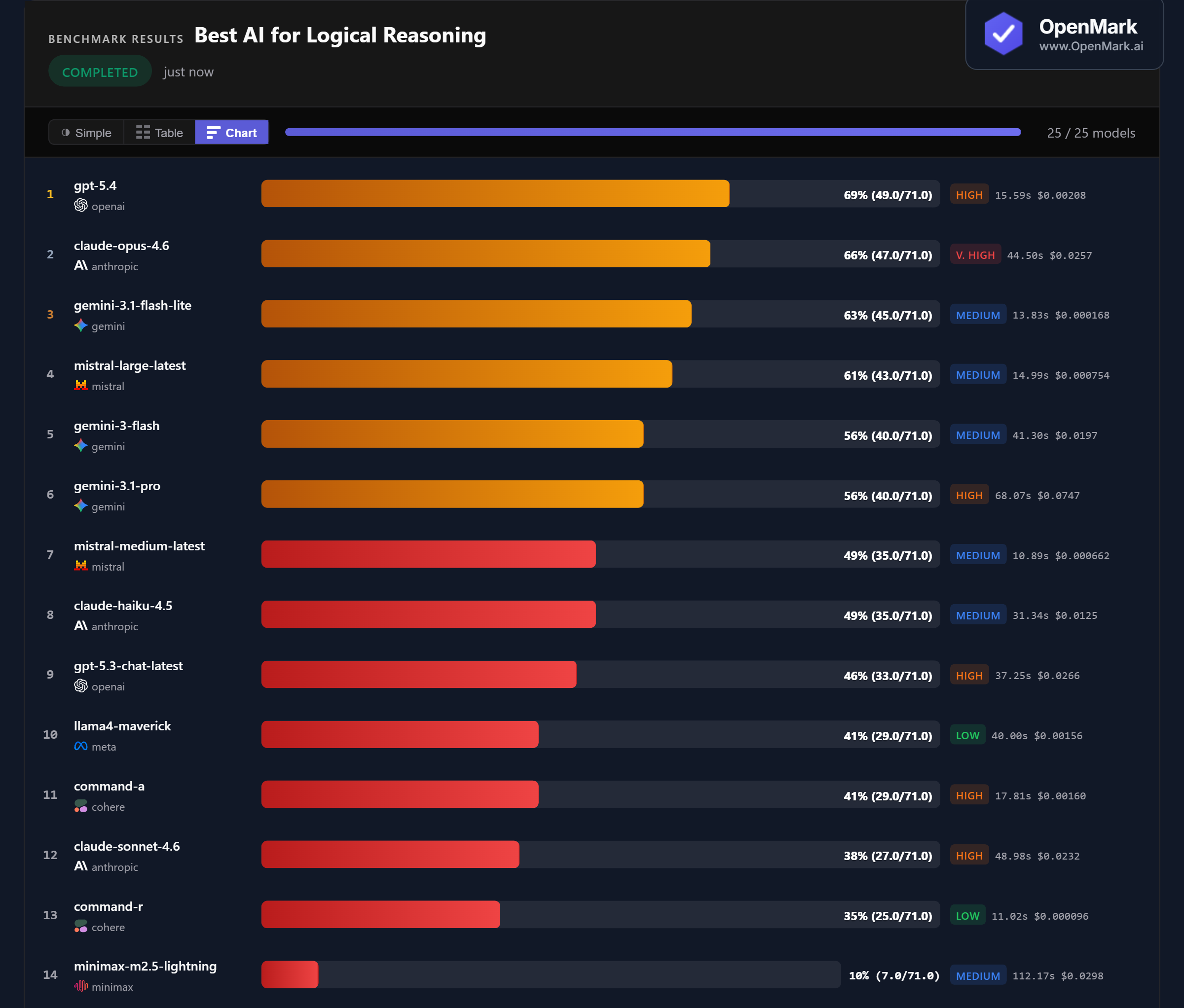
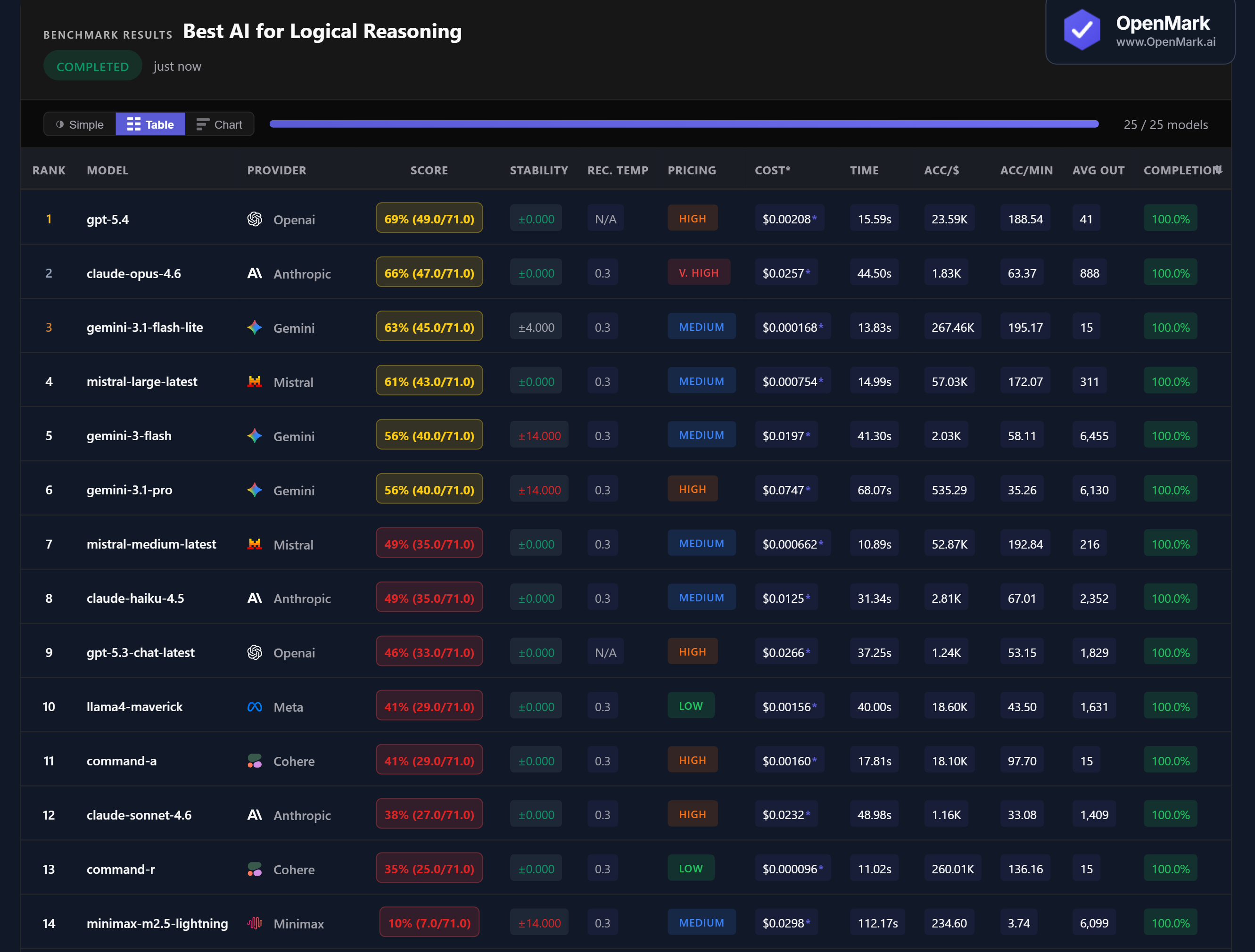
🏆 Accuracy: GPT-5.4 Leads, but No Model Breaks 70%
GPT-5.4 scored 69% (49.0/71.0), followed by Claude Opus 4.6 at 66% and Gemini 3.1 Flash Lite at 63%. No model cracked 70% — the hardest constraint puzzles and knights-and-knaves problems defeated every model. 11 of 25 models failed to even complete all tests, the highest failure rate across any benchmark category.
💰 Cost Efficiency: Gemini Flash Lite Delivers 63% for Near-Zero Cost
Gemini 3.1 Flash Lite scored 63% at $0.000168/run — accuracy-per-dollar of 267,459. That's 3rd place overall at 12x cheaper than GPT-5.4 ($0.00208) and 150x cheaper than Claude Opus ($0.0257). Flash Lite scores only 6 points behind the leader while costing virtually nothing. Mistral Large at 61% and $0.000754 also delivers strong value (57,029 Acc/$).
⚡ Speed: Mistral Medium Is the Fastest Reasoner
Mistral Medium Latest responded in 10.89s with 49% accuracy — the fastest model in the test. Command-R was nearly as fast at 11.02s (35%). Among the top 3, Gemini Flash Lite at 13.83s was the quickest and GPT-5.4 at 15.59s was reasonably fast. Claude Opus — despite scoring 2nd — took 44.50s, nearly 3x slower than GPT-5.4 for slightly lower accuracy.
📉 Claude Sonnet Scores Lower Than Claude Haiku
Claude Sonnet 4.6 scored 38% — below Claude Haiku 4.5's 49%. The more expensive Claude model performed worse on logical reasoning than the budget Claude model. Sonnet costs nearly double Haiku ($0.0232 vs $0.0125) while scoring 11 percentage points lower. Meanwhile, Claude Opus (66%) costs just slightly more than Sonnet but dramatically outperforms it.
Why These Results May Surprise You
Logical reasoning is the hardest benchmark category we've tested. The highest score was 69%, and almost half the models couldn't finish all tests. Here's why:
The high failure-to-complete rate makes this benchmark uniquely revealing. It tests not just accuracy, but whether a model can deliver a concise answer under real-world constraints — something many reasoning-focused models fail to do.
⚖️ Generic Benchmarks vs. Custom Benchmarks
These results are a directional signal, not a universal reasoning ranking. This benchmark deliberately escalates difficulty from trivial to extremely hard, with weighted scoring that penalizes models that only handle easy problems. A benchmark focused on one reasoning type (e.g., only syllogisms or only arithmetic) would produce very different rankings.
The 69% ceiling — and 44% failure-to-complete rate — reveal something important: logical reasoning is still a genuine differentiator between models. Unlike sentiment analysis or classification where many models cluster near identical scores, reasoning produces dramatic spread. This makes it especially important to benchmark on your specific reasoning needs.
These results are valid for this task design and scoring setup. Change the task, constraints, or scoring, and rankings can change — which is exactly why custom benchmarking matters.
Frequently Asked Questions
Which AI model is best for logical reasoning in 2026?
On our benchmark, GPT-5.4 scored highest at 69%, followed by Claude Opus 4.6 at 66% and Gemini 3.1 Flash Lite at 63%. No model broke 70% — the hardest constraint and deduction tasks defeated every model tested. The best model for your specific reasoning tasks depends on difficulty and task type. Run your own benchmark to find out.
Can AI solve logic puzzles?
Partially. AI models handle basic syllogisms and arithmetic reasoning well, but struggle with multi-step constraint satisfaction and knights-and-knaves puzzles. The top model scored 69% — and 11 of 25 models failed to complete all tests. Reasoning tasks are where AI models show the widest performance gaps.
Is GPT or Claude better at reasoning?
GPT-5.4 (69%) outperformed all Claude models. Claude Opus 4.6 scored 66% at 12x the cost. Surprisingly, Claude Sonnet 4.6 scored only 38% — lower than Claude Haiku 4.5 (49%). The more expensive Claude model performed worse on logical reasoning than the budget one.
What is the cheapest AI for reasoning tasks?
Gemini 3.1 Flash Lite scored 63% at $0.000168/run — 3rd place at 267,459 Acc/$. Mistral Large scored 61% at $0.000754. Both are in the Medium pricing tier and outperform many High and Very High tier models on reasoning tasks.
How does OpenMark benchmark logical reasoning?
Ten reasoning tasks with steeply weighted difficulty — from 1-point syllogisms to 18-point constraint puzzles. Scoring uses exact_match and numeric_from_text with zero tolerance. Harder tasks earn exponentially more points, so models that only solve easy problems score low. Results are 100% reproducible. Try it yourself for free.
Can OpenMark just do this for me?
Yes — for logical reasoning, the done-for-you audit is from $299 with 48-hour turnaround. Send your task definition, sample inputs, and pass/fail criteria; we benchmark it across all relevant models (up to 30+) and return a report with the recommended primary, fallbacks, and cost projections at your volume. See the audit service →
Why Teams Use OpenMark AI
You define the evaluation in your words, for your use case. Not MMLU, not HumanEval — your actual prompts, your actual data.
Multiple runs per model with variance tracking. A model that scores 90 once and 60 the next isn't the same as one that scores 85 every time.
See which model is cheapest for your task — scored against quality, not just raw price-per-token.
No accounts with OpenAI, Anthropic, or Google required. OpenMark AI handles every API call — just describe your task and run.
Don't want to design the test yourself? Have us run it for you.
If you don't want to design the logical reasoning test yourself or maintain it as new models ship — we run it for you on your data. Send us your task, we benchmark it across all relevant models (up to 30+) and send back a synthesized report with the recommended primary, fallbacks, cost-at-volume, and re-test triggers. From $299, 48-hour turnaround, no call required.
Benchmark AI Models on Your Reasoning Tasks
Test which model handles YOUR logic puzzles, deductions, and reasoning chains best.
Build custom benchmarks for any task — text, code, structured output, classification, images, and more.
50 free credits — no API keys, no setup.