Best AI for JSON Generation
in 2026
30 AI models benchmarked on JSON schema compliance — flat objects, nested arrays, recursive structures, regex patterns, conditional logic, and extreme constraints. Two models scored 100%. Most couldn't clear 70%.
What This Benchmark Tests (and Does Not Test)
All models tested with default API configurations. 11 of 30 models failed to complete all tests — complex JSON schema constraints caused timeouts or malformed responses. Scoring validates structure, not semantic content.
Benchmark Results
Key Findings
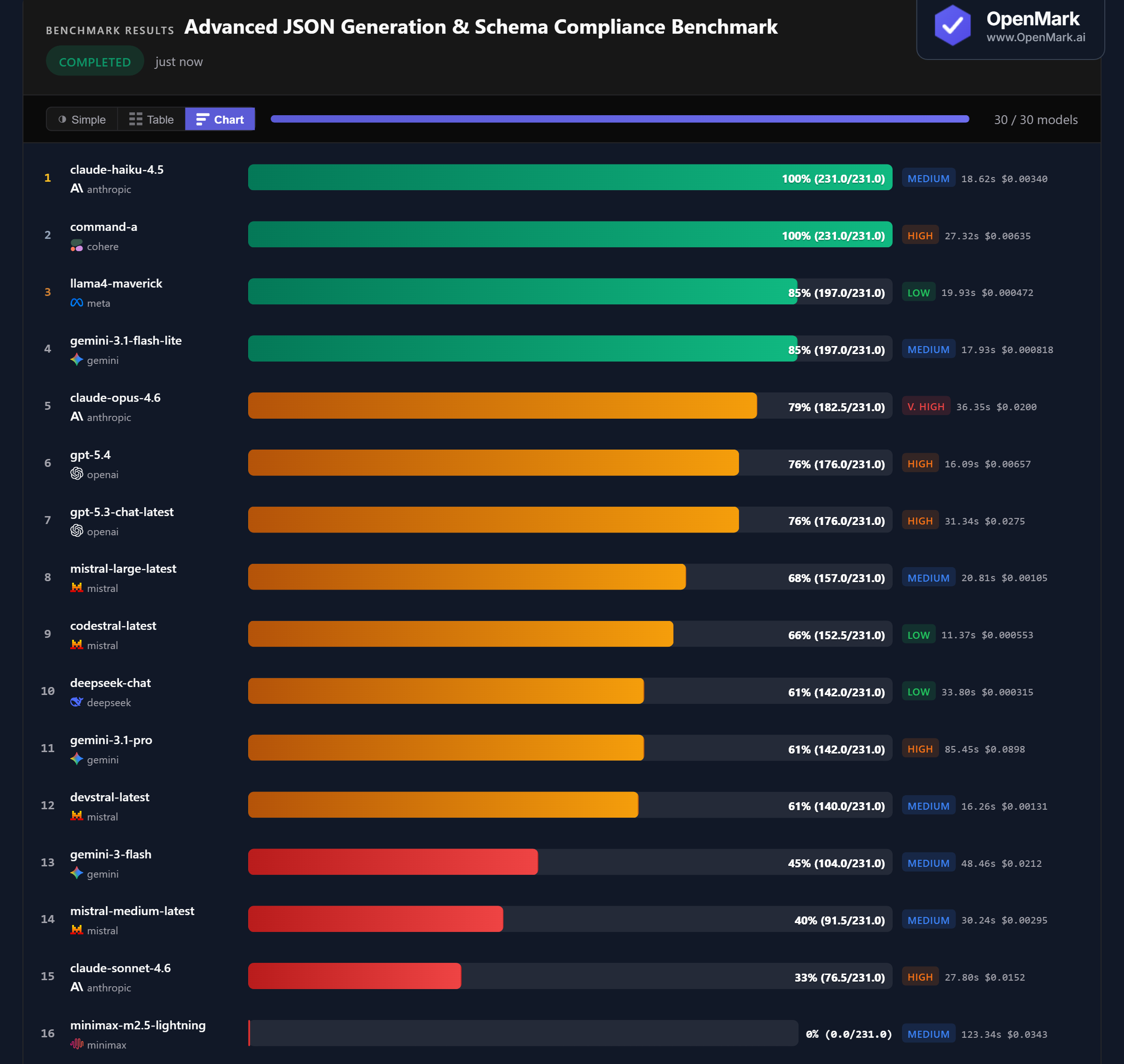
🏆 Two Perfect Scores: Claude Haiku 4.5 & Command-A Ace Every Schema Test
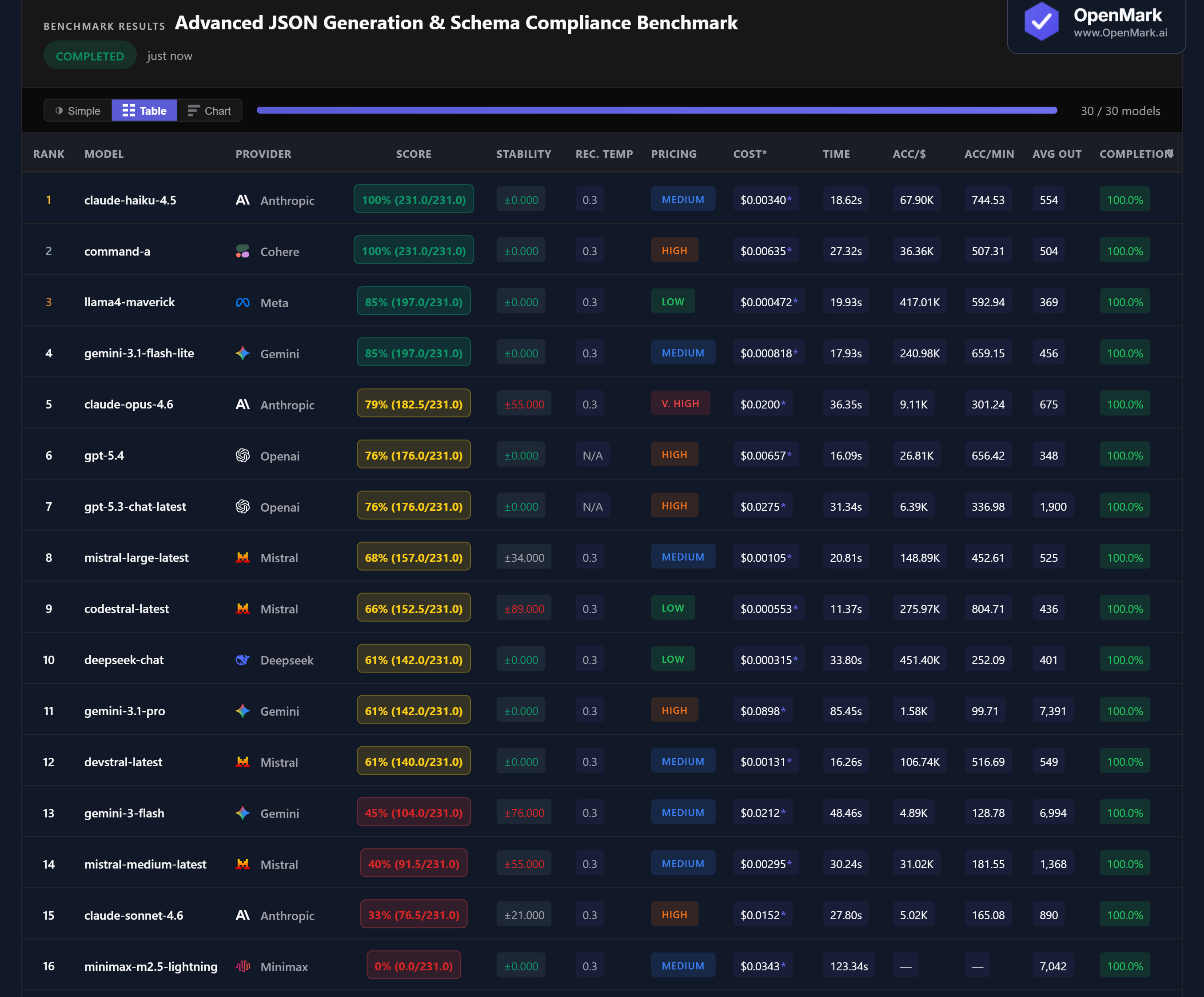
Claude Haiku 4.5 and Command-A both scored 100% (231/231) with perfect stability (±0). Both models produced valid JSON for all 10 tests — flat objects, recursive structures, regex patterns, conditional constraints, and even the extreme edge cases. Haiku is the cheaper winner at $0.0034/run (Medium tier) vs Command-A's $0.0064 (High tier), and faster at 18.6s vs 27.3s.
💰 Cost Efficiency: Llama4 Maverick Delivers 85% for Under $0.001
Llama4 Maverick scored 85% at $0.000472/run — accuracy-per-dollar of 417,011. That's the best cost efficiency in the entire benchmark. Gemini 3.1 Flash Lite also scored 85% at $0.000818 (240,979 Acc/$). Both Low/Medium-tier models outperformed GPT-5.4 (76%, $0.00657), GPT-5.3 (76%, $0.0275), and Claude Opus (79%, $0.0200). For users who don't need a perfect score, these budget models cover 85% of schema requirements at a fraction of the cost.
📉 Claude's Inverted Hierarchy: The Cheapest Model Wins
Claude Haiku 4.5 (100%) > Claude Opus 4.6 (79%) > Claude Sonnet 4.6 (33%). Anthropic's cheapest model scored perfect while the mid-tier model scored only 33%. Haiku costs $0.0034, Sonnet costs $0.0152 (4.5x more), and Opus costs $0.0200 (6x more). On JSON generation, bigger Claude models don't just fail to improve — they actively perform worse. Opus also showed instability at ±55, while Haiku was perfectly stable.
⚡ Stability: Some Models Produce Wildly Different JSON Between Runs
Codestral scored ±89, Gemini Flash ±76, Claude Opus ±55, Mistral Medium ±55 — massive variance. For a deterministic output format like JSON, instability means a model might produce valid JSON on one run and wrap it in markdown code fences or add explanatory text on the next. The leaders (Haiku, Command-A, Maverick, Flash Lite, GPT-5.4) were all perfectly stable at ±0. For production JSON APIs, stability matters as much as accuracy.
Why These Results May Surprise You
JSON generation sounds straightforward — but this benchmark reveals dramatic differences. Two models scored 100% while others couldn't clear 40%. Here's why:
The pattern is clear: for structured output, you want a model that follows formatting instructions precisely and consistently. The most expensive, most capable models aren't necessarily the best at this.
⚖️ Generic Benchmarks vs. Custom Benchmarks
These results are a directional signal, not a universal JSON-generation ranking. This benchmark deliberately escalates from trivial schemas to extreme edge cases, with Fibonacci weighting that makes the hardest tests overwhelmingly important. A benchmark focused only on common API response formats would produce different rankings.
Two models achieving 100% with perfect stability is remarkable — and practically useful. But even the 85% models (Maverick, Flash Lite) may handle your specific schemas perfectly if your use case doesn't involve recursive structures or regex constraints. The only way to know is to test your actual schemas.
These results are valid for this task design and scoring setup. Change the schemas, constraints, or weighting, and rankings can change — which is exactly why custom benchmarking matters.
Frequently Asked Questions
Which AI model is best for JSON generation in 2026?
On our benchmark, Claude Haiku 4.5 and Command-A both scored 100% with perfect stability. Both handled all 10 schema tests including recursive structures, regex patterns, and conditional constraints. Claude Haiku is the cheaper and faster of the two. Run your own benchmark to test your specific schemas.
Can AI models generate valid JSON reliably?
It varies dramatically. Two models scored 100% while Claude Sonnet 4.6 scored only 33% and Minimax scored 0%. Simple flat schemas are easy for most models; advanced constraints like conditional logic and regex patterns are where many fail. Stability also varies — some models produce valid JSON on one run and invalid output on the next.
Is Claude or GPT better at structured output?
Claude Haiku 4.5 scored 100% — the best result. But Claude Sonnet 4.6 scored only 33%, lower than GPT-5.4's 76%. Within Anthropic's lineup, the cheapest model (Haiku) dramatically outperformed the mid-tier (Sonnet) and premium (Opus, 79%). For structured output, model family matters less than the specific model.
What is the cheapest AI for JSON generation?
Llama4 Maverick scored 85% at $0.000472/run — the best cost efficiency at 417,011 Acc/$. Gemini 3.1 Flash Lite also scored 85% at $0.000818. For perfect 100% accuracy, Claude Haiku 4.5 at $0.0034 is the cheapest option. All three are cheaper than GPT-5.4 ($0.00657, 76%).
How does OpenMark benchmark JSON generation?
Ten tests with Fibonacci-weighted difficulty — from flat objects (1 point) to extreme constraints (89 points). Scoring uses json_schema validation against defined schemas: type checking, enum, regex patterns, conditional required fields, array length constraints. Fully deterministic — no LLM-as-judge. Try it yourself for free.
Can OpenMark just do this for me?
Yes — for JSON generation, the done-for-you audit is from $299 with 48-hour turnaround. Send your task definition, sample inputs, and pass/fail criteria; we benchmark it across all relevant models (up to 30+) and return a report with the recommended primary, fallbacks, and cost projections at your volume. See the audit service →
Why Teams Use OpenMark AI
You define the evaluation in your words, for your use case. Not MMLU, not HumanEval — your actual prompts, your actual data.
Multiple runs per model with variance tracking. A model that scores 90 once and 60 the next isn't the same as one that scores 85 every time.
See which model is cheapest for your task — scored against quality, not just raw price-per-token.
No accounts with OpenAI, Anthropic, or Google required. OpenMark AI handles every API call — just describe your task and run.
Don't want to design the test yourself? Have us run it for you.
If you don't want to design the JSON generation test yourself or maintain it as new models ship — we run it for you on your data. Send us your task, we benchmark it across all relevant models (up to 30+) and send back a synthesized report with the recommended primary, fallbacks, cost-at-volume, and re-test triggers. From $299, 48-hour turnaround, no call required.
Benchmark AI Models on Your Structured Output
Test which model produces the cleanest JSON for YOUR schemas, YOUR constraints, YOUR validation rules.
Build custom benchmarks for any task — text, code, structured output, classification, and more.
50 free credits — no API keys, no setup.