Best AI for Legal Documents
in 2026
Top 29 AI models benchmarked on legal document evaluation — contract review, e-discovery, multi-jurisdictional compliance, M&A due diligence, and structured recommendations. Gemini 3.1 Pro scored a perfect 100%, but 11 of 29 models failed entirely. Legal AI is high-stakes.
What This Benchmark Tests (and Does Not Test)
All models tested with default API configurations. 11 of 29 models scored 0% or failed to complete all tests. This benchmark evaluates whether a model can reason about legal AI tool selection, not whether it can practice law.
Benchmark Results
Key Findings
🏆 Perfect Score: Gemini 3.1 Pro Aces Every Legal Test
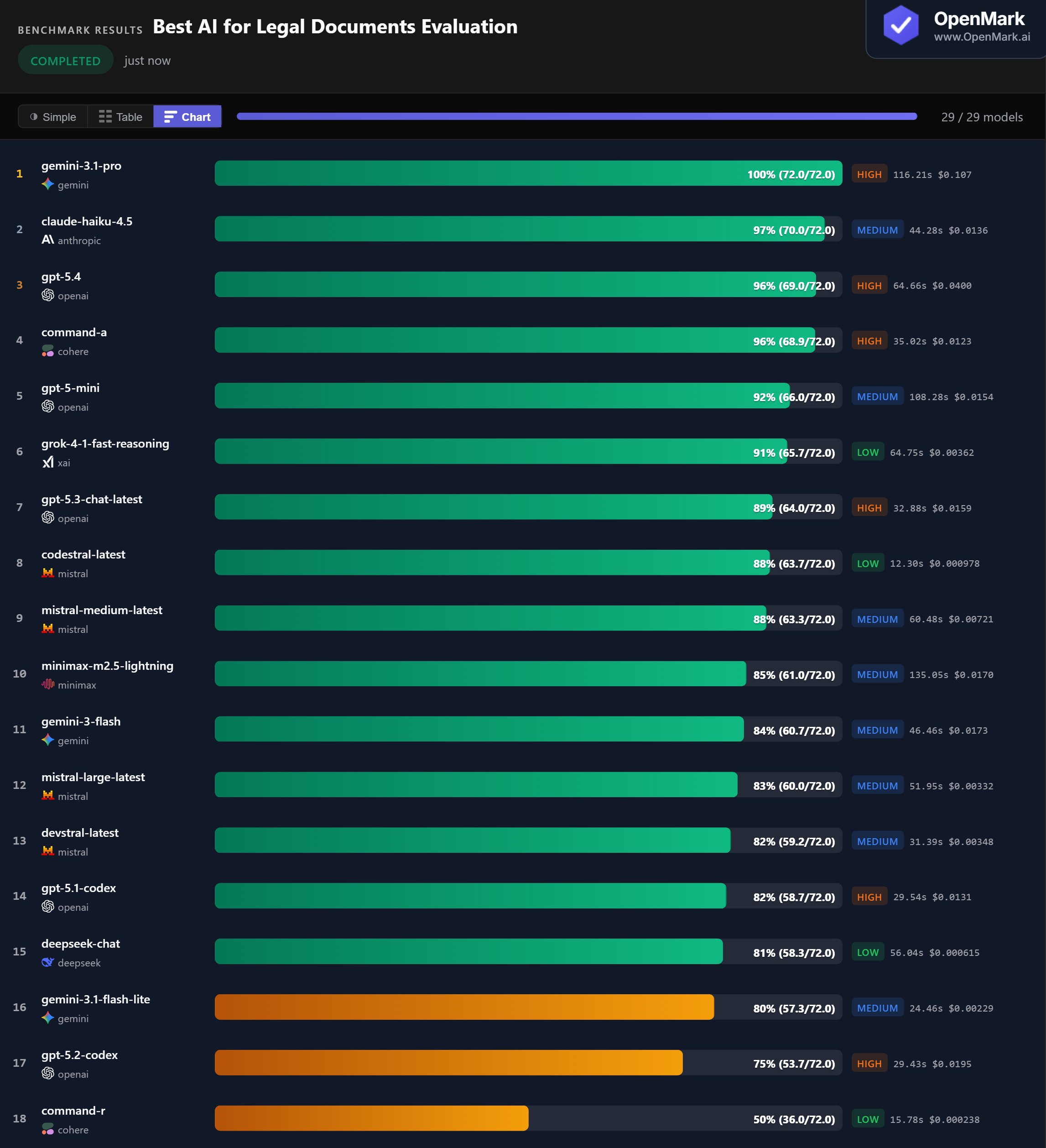
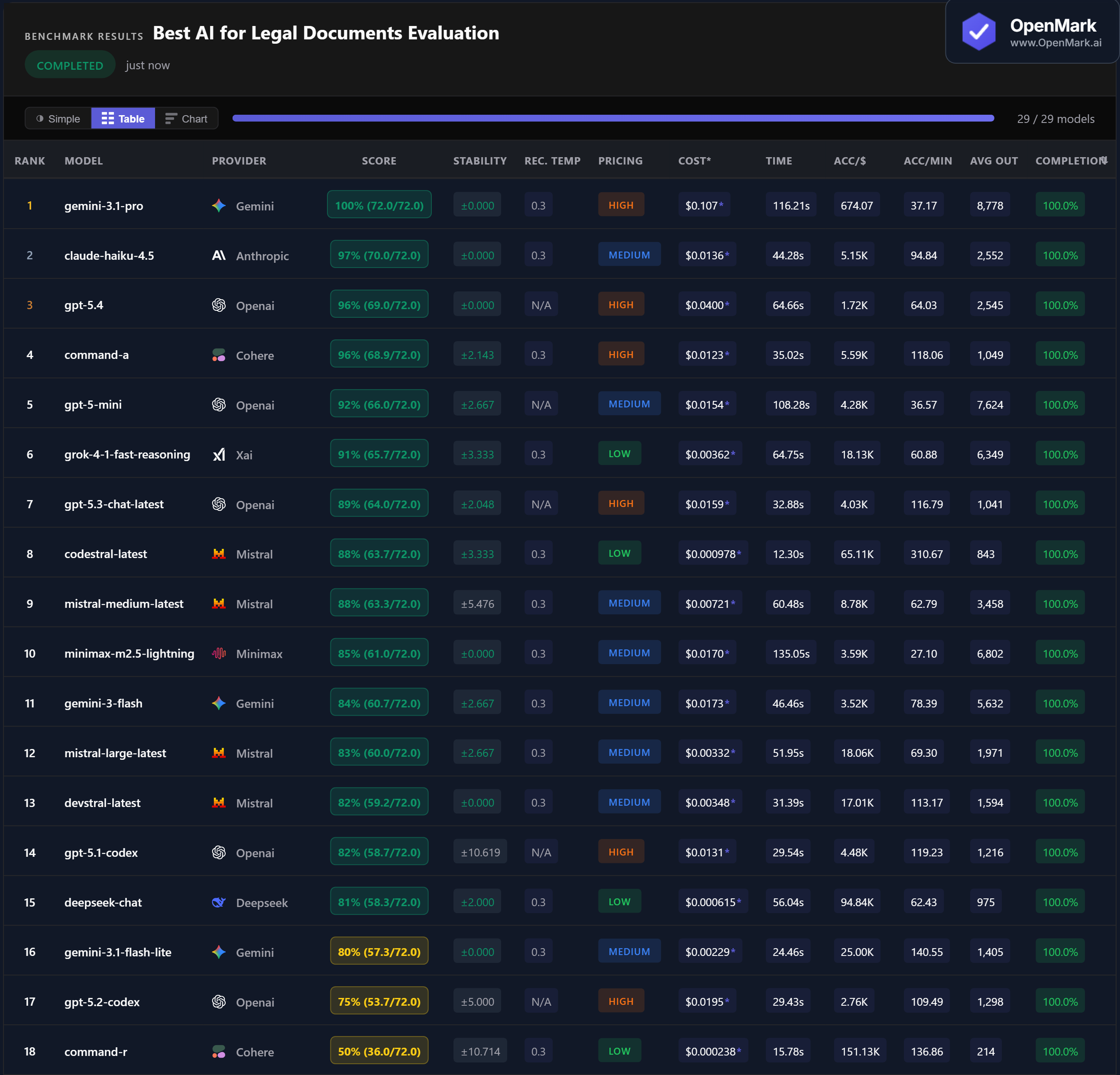
Gemini 3.1 Pro scored 100% (72.0/72.0) with zero variance across runs — the only model to answer every legal evaluation test correctly. Claude Haiku 4.5 followed closely at 97%, then GPT-5.4 and Command-A both at 96%. The top 4 models are tightly clustered, but only one achieved a perfect score.
💰 The Sweet Spot: Claude Haiku 4.5 at 97% for $0.014
Claude Haiku 4.5 scored 97% at $0.0136 per run — roughly 1/8th the cost of Gemini Pro ($0.107) with only 3% lower accuracy. It also showed perfect stability (±0.000) and was 2.6x faster at 44.3 seconds. For most legal document workflows, Claude Haiku offers the strongest balance of accuracy, cost, and reliability. Command-A matched at 96% for $0.0123 with similarly strong performance.
⚡ Budget Stars: Codestral at 88% for Under $0.001
Codestral scored 88% at $0.000978 per run and was the fastest model at 12.3 seconds (310 Acc/min). DeepSeek Chat scored 81% at $0.000615 — the highest accuracy-per-dollar in the benchmark at 94,837. Both are Low-tier models that outperform several High-tier alternatives. For teams needing volume processing at lower cost, these models deliver strong results at roughly 1/100th of Gemini Pro's price.
📉 High Failure Rate: 11 of 29 Models Scored Zero
Legal document evaluation proved to be one of the most demanding benchmark categories — 11 models failed entirely. Qwen models, GPT-5-Nano, GPT-5.4 Pro, DeepSeek Reasoner, Grok-4, GLM-5, and Codex Mini all scored 0%. Claude Opus 4.6 scored only 2.8% with 10% completion. Even Claude Sonnet 4.6, a capable model, only reached 79% with 45% completion. Legal evaluation demands domain-specific reasoning that not every model can handle.
Why These Results May Surprise You
A coding model in the top 8 on a legal benchmark. A budget model outperforming Anthropic's flagship. Here is why:
The high failure rate (11 of 29 models) combined with the tight top cluster (4 models between 96-100%) makes legal document evaluation a clear capability separator. Models either handle it well or fail entirely — there is little middle ground.
Generic Benchmarks vs. Custom Benchmarks
These results are a directional signal, not a definitive legal AI ranking. This benchmark tests whether models can reason about legal tool selection and produce structured outputs for legal scenarios. It does not test actual legal accuracy, case law retrieval, or compliance with specific jurisdictions.
The practical takeaway: Claude Haiku 4.5 is the standout performer. It scores 97% at 1/8th the cost of the only model that beats it, with perfect stability and reasonable speed. For teams that need guaranteed perfection, Gemini 3.1 Pro is the only option — but the cost premium is steep.
These results are valid for this task design and scoring setup. Change the legal scenarios, the required concepts, or the scoring criteria, and rankings can change — which is exactly why custom benchmarking matters.
Frequently Asked Questions
Which AI model is best for legal document evaluation in 2026?
On our benchmark, Gemini 3.1 Pro scored a perfect 100% with zero variance. Claude Haiku 4.5 followed at 97% for roughly 1/8th the cost. GPT-5.4 and Command-A both scored 96%. The best choice depends on your budget — Claude Haiku offers the strongest balance for most legal workflows. Run your own legal benchmark to find out.
Can AI handle complex legal document analysis?
It depends on the model. 18 of 29 models completed all tests, and the top 6 scored above 91%. But 11 models scored 0% or failed entirely. The tests covered privileged contract review, multi-jurisdictional compliance, M&A due diligence, e-discovery, and structured JSON output. Legal AI is demanding, and model selection matters significantly.
What is the cheapest AI for legal document review?
DeepSeek Chat scored 81% at $0.000615 per run — the highest accuracy-per-dollar at 94,837 Acc/$. Codestral scored 88% at $0.000978 and was the fastest model at 12.3 seconds. Both outperform many premium models and cost roughly 1/100th of Gemini Pro's price per run.
Is AI reliable enough for legal work?
Reliability varies by model. Gemini Pro, Claude Haiku, GPT-5.4, and several others showed perfect stability (zero variance). But some models like GPT-5.1 Codex (±10.6) and Command-R (±10.7) had high variance. For legal work, stability matters as much as accuracy. Always verify AI outputs with human review.
How does OpenMark AI benchmark legal document evaluation?
Ten tests covering contract review, e-discovery, compliance, due diligence, and structured output. Scoring uses contains_all, contains_any, exact_match, and json_schema modes with partial credit. Tests require models to include specific legal concepts like confidentiality, auditability, and jurisdiction-awareness. Fully deterministic. Try it yourself for free.
Can OpenMark just do this for me?
Yes — for legal document analysis, the done-for-you audit is from $299 with 48-hour turnaround. Send your task definition, sample inputs, and pass/fail criteria; we benchmark it across all relevant models (up to 30+) and return a report with the recommended primary, fallbacks, and cost projections at your volume. See the audit service →
Why Teams Use OpenMark AI
You define the evaluation in your words, for your use case. Not MMLU, not HumanEval — your actual legal prompts, your actual document scenarios.
Multiple runs per model with variance tracking. A model that scores 90 once and 60 the next is not the same as one that scores 85 every time.
See which model is cheapest for your task — scored against quality, not just raw price-per-token.
No accounts with OpenAI, Anthropic, or Google required. OpenMark AI handles every API call — just describe your task and run.
Don't want to design the test yourself? Have us run it for you.
If you don't want to design the legal document analysis test yourself or maintain it as new models ship — we run it for you on your data. Send us your task, we benchmark it across all relevant models (up to 30+) and send back a synthesized report with the recommended primary, fallbacks, cost-at-volume, and re-test triggers. From $299, 48-hour turnaround, no call required.
Benchmark AI on Your Legal Documents
Test which model handles YOUR contracts, YOUR compliance requirements, YOUR legal workflows.
Build custom benchmarks for any task — text, code, structured output, classification, images, and more.
50 free credits — no API keys, no setup.