Best AI for SQL Generation
in 2026
30 AI models benchmarked on SQL generation — joins, window functions, recursive CTEs, cohort analysis, and temporal graph queries. GPT-5.3 led at 94%, but 13 models scored above 85%. The tightest race of any benchmark category.
What This Benchmark Tests (and Does Not Test)
All models tested with default API configurations. 14 of 30 models failed to complete all tests. Scoring checks for required SQL patterns and keywords — it validates structural correctness, not execution against a live database.
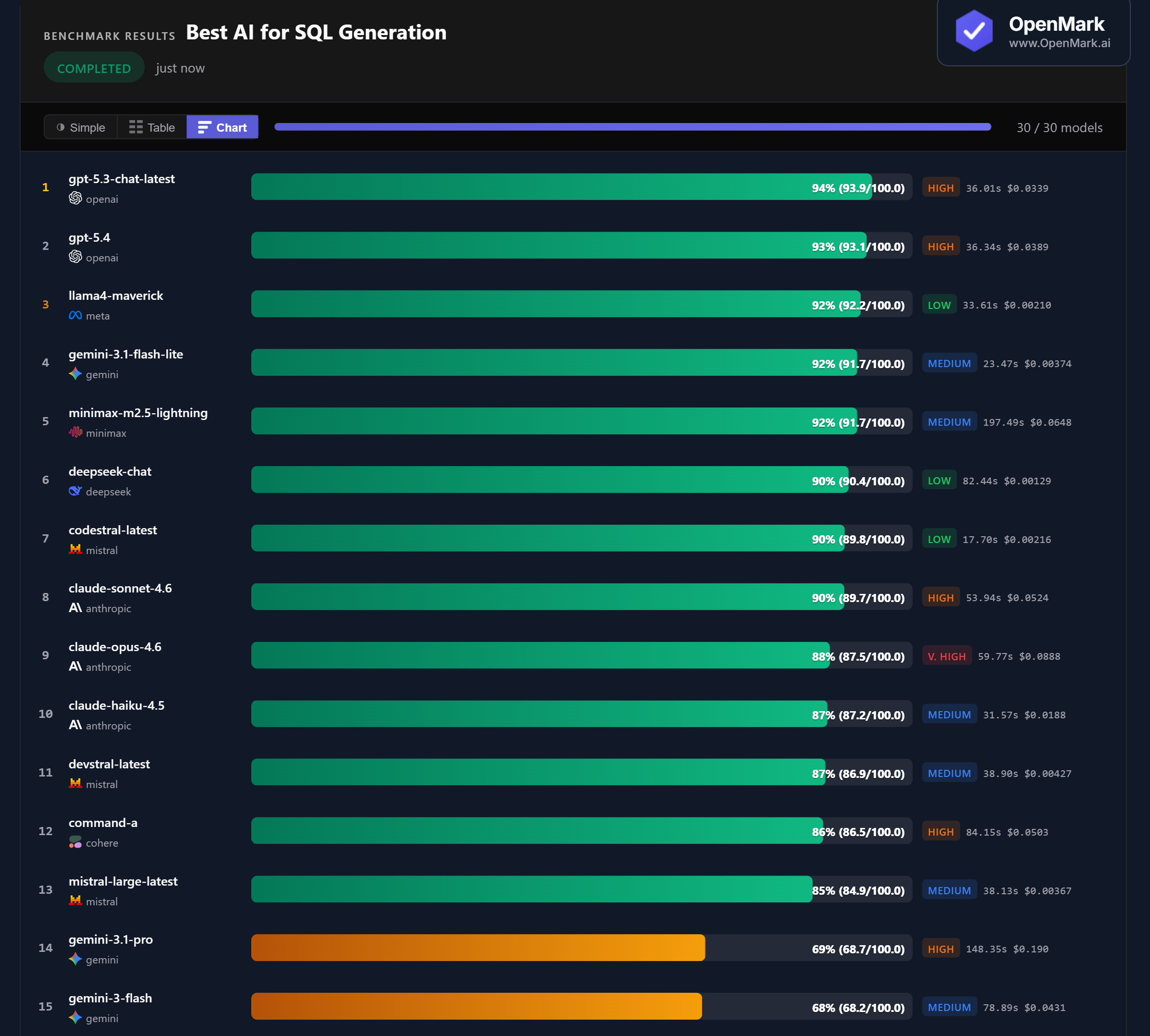
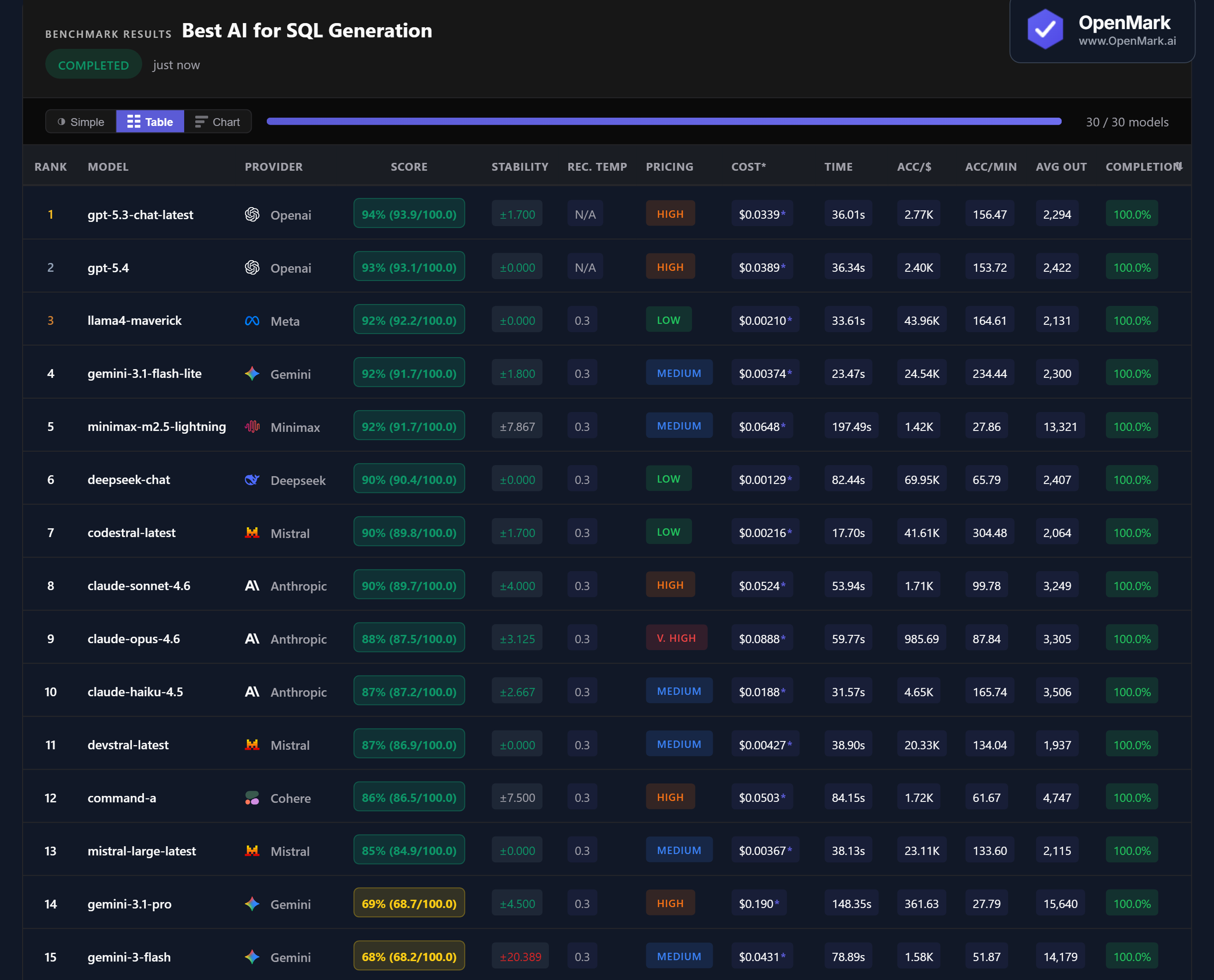
Benchmark Results
Key Findings
🏆 The Tightest Race: 13 Models Score Above 85%
GPT-5.3 Chat led at 94% (93.9/100), but only 9 points separate 1st from 13th place. GPT-5.4 followed at 93%, then Llama4 Maverick and Gemini Flash Lite tied at 92%. SQL generation is the most competitive benchmark category — 13 models clustered between 85-94%. Then a sharp cliff: rank 14 (Gemini Pro) drops to 69%. Models either handle advanced SQL well, or they don't.
💰 Cost Efficiency: DeepSeek Delivers 90% for $0.0013 Per Run
DeepSeek Chat scored 90% at $0.00129/run — accuracy-per-dollar of 69,951. That's the highest cost efficiency in the benchmark. Llama4 Maverick scored 92% at $0.00210 (43,956 Acc/$), and Codestral scored 90% at $0.00216 (41,615 Acc/$). All three Low-tier models match or outperform Claude Sonnet (90%, $0.0524) at 24-41x less cost. For SQL generation, budget models deliver premium results.
⚡ Speed: Codestral Generates SQL in 17.7 Seconds
Codestral scored 90% in 17.7s — 304 Acc/min, the fastest model by a wide margin. Gemini Flash Lite came second at 23.5s (234 Acc/min). By contrast, Minimax took 197.5s for the same 92% score — over 11x slower than Codestral. For production SQL pipelines where latency matters, Codestral and Flash Lite are the clear choices. Claude Haiku at 31.6s and GPT-5.4 at 36.3s offer a good balance of speed and accuracy.
📉 Gemini's Cliff: Pro Scores 69% at $0.19 Per Run
Gemini 3.1 Pro scored 69% at $0.190/run — the most expensive model in the benchmark by far, yet ranked 14th. Gemini Flash scored 68% at $0.043. Both sit 16+ points behind the 85% cluster above them. Meanwhile, Gemini Flash Lite scored 92% at $0.0037 — outperforming both by a massive margin at a fraction of the cost. Within Google's lineup, Flash Lite is the clear SQL winner.
Why These Results May Surprise You
SQL generation produced the tightest top cluster of any benchmark — 13 models within 9 points. But below that cluster, scores collapse. Here's why:
The tight competition at the top and the sharp cliff below it suggest that SQL generation is a binary skill for LLMs — most modern models either handle it well or fail entirely. The differentiator isn't whether a model can write SQL, but whether it can handle the advanced patterns your specific queries require.
⚖️ Generic Benchmarks vs. Custom Benchmarks
These results are a directional signal, not a universal SQL-generation ranking. This benchmark tests 10 specific SQL patterns with escalating complexity. A benchmark focused on simpler SELECT/WHERE queries would show even tighter clustering. A benchmark using dialect-specific syntax (MySQL, T-SQL, BigQuery) or testing against a live database would produce different rankings.
The tight 85-94% cluster is practically useful — it means you have real choices among budget models. Llama4 Maverick, DeepSeek Chat, and Codestral all score 90%+ at under $0.003 per run. For most SQL generation workflows, you don't need to pay premium prices.
These results are valid for this task design and scoring setup. Change the SQL dialect, the query patterns, or the scoring criteria, and rankings can change — which is exactly why custom benchmarking matters.
Frequently Asked Questions
Which AI model is best for SQL generation in 2026?
On our benchmark, GPT-5.3 Chat scored highest at 94%, narrowly ahead of GPT-5.4 at 93%. But 13 models scored above 85%, making this the most competitive benchmark category. Llama4 Maverick matched the leaders at 92% for a fraction of the cost. The best model depends on your budget and query complexity. Run your own SQL benchmark to find out.
Can AI write complex SQL queries?
Yes — 13 models scored above 85% on tests including recursive CTEs, window functions, cohort analysis, and temporal joins. The hardest test (temporal graph cycle detection) is where models differentiate. Even budget models like DeepSeek (90%) and Codestral (90%) handle advanced SQL patterns well. 14 of 30 models failed to complete all tests, suggesting SQL competency varies widely.
Is GPT or Claude better at writing SQL?
GPT models scored slightly higher: GPT-5.3 at 94%, GPT-5.4 at 93%. Claude Sonnet scored 90%, Opus 88%, Haiku 87%. The gap is small (4-7 points) but consistent. Notably, Claude Sonnet outperformed Opus on SQL — the cheaper Claude model wrote better SQL than the premium one.
What is the cheapest AI for SQL generation?
DeepSeek Chat scored 90% at $0.00129/run — the best cost efficiency at 69,951 Acc/$. Llama4 Maverick scored 92% at $0.00210, and Codestral scored 90% at $0.00216. All three outperform models costing 20-40x more. For SQL generation, budget models deliver premium-quality results.
How does OpenMark benchmark SQL generation?
Ten SQL tasks with escalating complexity — from basic joins (3 points) to temporal graph cycle detection (18 points). Scoring uses contains_all with partial credit to check for required SQL patterns. Tests cover window functions, recursive CTEs, SCD2 temporal joins, conversion funnels, and more. Fully deterministic — no LLM-as-judge. Try it yourself for free.
Can OpenMark just do this for me?
Yes — for SQL generation, the done-for-you audit is from $299 with 48-hour turnaround. Send your task definition, sample inputs, and pass/fail criteria; we benchmark it across all relevant models (up to 30+) and return a report with the recommended primary, fallbacks, and cost projections at your volume. See the audit service →
Why Teams Use OpenMark AI
You define the evaluation in your words, for your use case. Not MMLU, not HumanEval — your actual prompts, your actual data.
Multiple runs per model with variance tracking. A model that scores 90 once and 60 the next isn't the same as one that scores 85 every time.
See which model is cheapest for your task — scored against quality, not just raw price-per-token.
No accounts with OpenAI, Anthropic, or Google required. OpenMark AI handles every API call — just describe your task and run.
Don't want to design the test yourself? Have us run it for you.
If you don't want to design the SQL generation test yourself or maintain it as new models ship — we run it for you on your data. Send us your task, we benchmark it across all relevant models (up to 30+) and send back a synthesized report with the recommended primary, fallbacks, cost-at-volume, and re-test triggers. From $299, 48-hour turnaround, no call required.
Benchmark AI Models on Your SQL Tasks
Test which model writes the cleanest SQL for YOUR schemas, YOUR queries, YOUR data models.
Build custom benchmarks for any task — text, code, structured output, classification, images, and more.
50 free credits — no API keys, no setup.