Best AI for Customer Support
in 2026
Top 29 AI models benchmarked on customer support evaluation — platform recommendations, CRM-native selection, governance requirements, multilingual routing, and nuanced tradeoff analysis. GPT-5 Mini and Minimax both scored a perfect 100%, but stability varied wildly across models.
What This Benchmark Tests (and Does Not Test)
All models tested with default API configurations. 10 of 29 models failed to complete all tests. This benchmark evaluates whether a model can reason about customer support platform selection and tradeoffs, not whether it can serve as a customer support chatbot itself.
Benchmark Results
Key Findings
🏆 Two Perfect Scores — From Medium-Tier Models
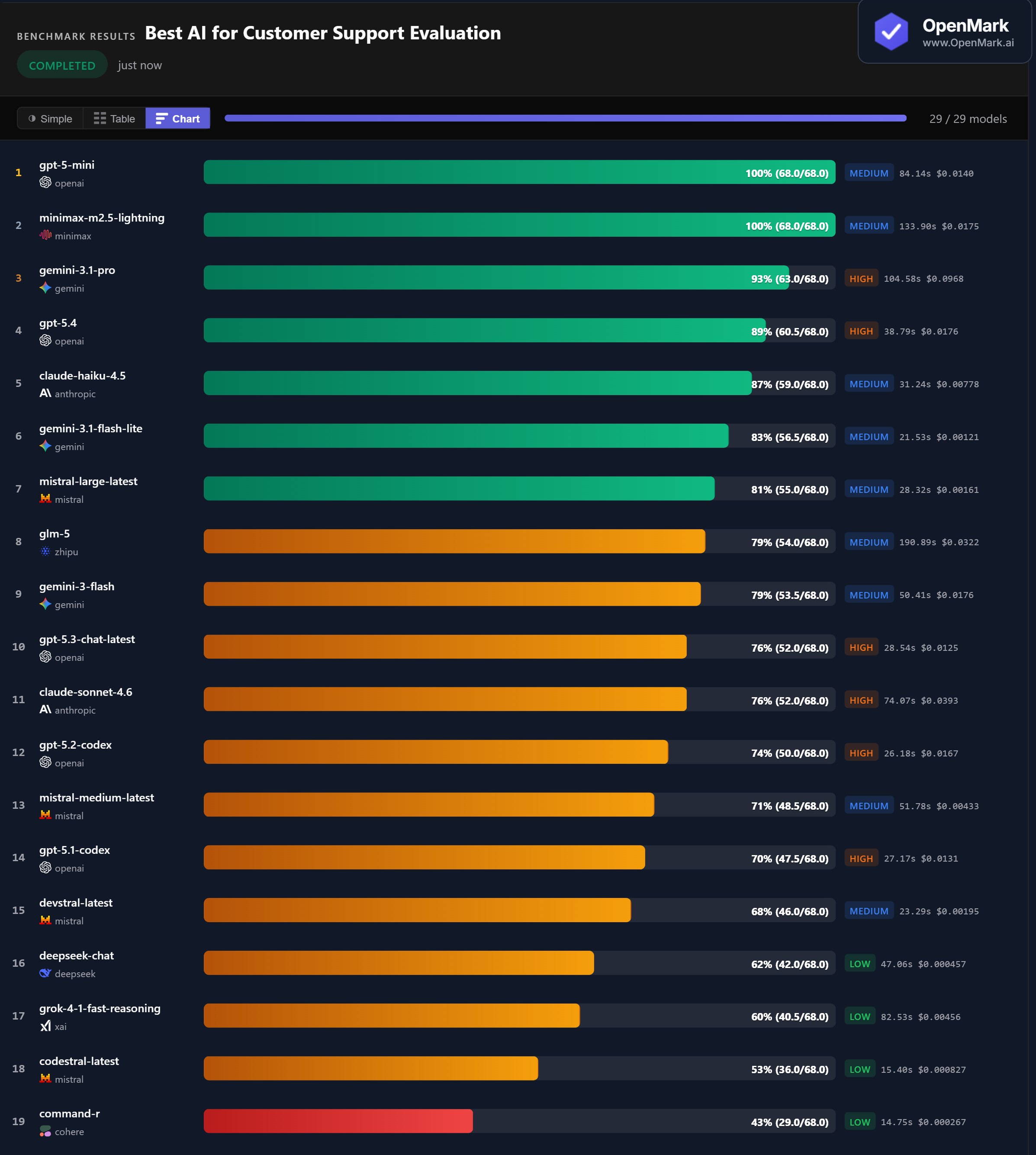
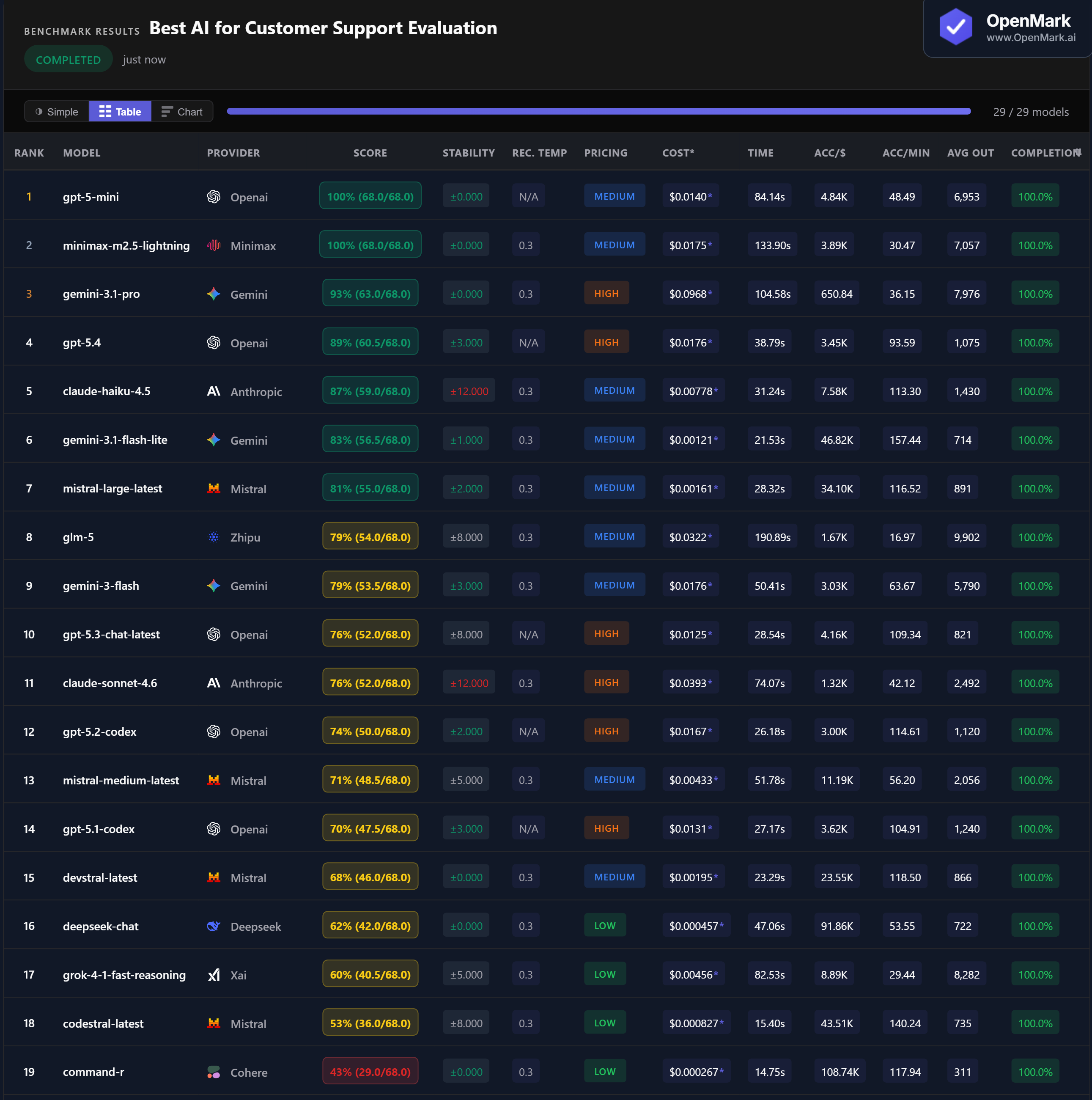
GPT-5 Mini and Minimax M2.5 Lightning both scored 100% (68.0/68.0) with zero variance. Both are Medium-tier models. GPT-5 Mini at $0.014/run was faster at 84 seconds; Minimax at $0.018/run was slower at 134 seconds but equally perfect. Gemini 3.1 Pro followed at 93% — but at $0.097/run, it costs 7x more than the models that beat it.
💰 Budget Champion: Flash Lite at 83% for $0.0012
Gemini 3.1 Flash Lite scored 83% at $0.00121/run — the best balance of cost and accuracy among budget models, at 46,820 Acc/$. Mistral Large followed at 81% for $0.00161 (34,100 Acc/$). DeepSeek Chat scored 62% at $0.000457 — the highest raw cost efficiency at 91,856 Acc/$. For teams processing high volumes, Flash Lite delivers over 80% accuracy at roughly 1/12th the cost of the perfect scorers.
⚠️ Stability Warning: Claude Models Swing ±12 Points
Claude Haiku 4.5 scored 87% but with ±12.000 variance — meaning scores ranged roughly 75-99% between runs. Claude Sonnet 4.6 showed the same ±12.000 instability at 76%. GPT-5.3 and GLM-5 had ±8.000. For customer support workflows where consistent answers matter, these models are risky despite their accuracy averages. The perfect scorers (GPT-5 Mini, Minimax) and several mid-range models (Devstral, DeepSeek, Command-R) all had zero variance.
📉 Smaller Models Beat Bigger Siblings — Twice
GPT-5 Mini (100%) outscored GPT-5.4 (89%) by 11 points. Claude Haiku (87%) outscored Claude Sonnet (76%) by 11 points. In both cases, the cheaper, smaller model was more accurate on customer support tasks. GPT-5.3 Chat (76%, ±8) scored lower than GPT-5 Mini (100%, ±0) across every dimension — accuracy, stability, and cost. Bigger and more expensive does not mean better for this category.
Why These Results May Surprise You
Medium-tier models topping the chart. Premium flagships scoring lower than their budget counterparts. Here is why:
Customer support evaluation is fundamentally a test of structured business reasoning and instruction compliance. Models optimized for concise, multi-concept answers dominate — regardless of their price tier or parameter count.
Generic Benchmarks vs. Custom Benchmarks
These results are a directional signal, not a universal customer support AI ranking. This benchmark tests whether models can reason about platform selection and tradeoffs — it does not test actual customer-facing chatbot quality, ticket resolution speed, or conversation naturalness.
The practical takeaway: GPT-5 Mini is the clear winner — perfect accuracy, perfect stability, Medium-tier pricing, and reasonable speed. For budget-conscious teams, Gemini Flash Lite (83%, $0.0012) and Mistral Large (81%, $0.0016) offer strong alternatives at 1/10th the cost. Watch out for high-variance models — stability matters for support workflows.
These results are valid for this task design and scoring setup. Change the support scenarios, the required concepts, or the scoring criteria, and rankings can change — which is exactly why custom benchmarking matters.
Frequently Asked Questions
Which AI model is best for customer support evaluation in 2026?
On our benchmark, GPT-5 Mini and Minimax M2.5 Lightning both scored a perfect 100% with zero variance. Both are Medium-tier models — premium pricing does not guarantee better customer support reasoning. Gemini 3.1 Pro followed at 93% but at 7x the cost. Run your own support benchmark to find out what works for your use case.
Can AI reason about customer support platform selection?
Yes — 19 of 29 models completed all tests, and the top 7 scored above 81%. Tests covered enterprise platform selection, CRM-native fit, governance for regulated industries, multilingual routing, and nuanced tradeoff analysis. However, stability varies widely — some models swing ±12 points between runs.
What is the cheapest AI for customer support tasks?
Gemini 3.1 Flash Lite scored 83% at $0.00121/run — the best balance of cost and quality. DeepSeek Chat scored 62% at $0.000457 for the highest raw cost efficiency. Mistral Large scored 81% at $0.00161. All three deliver solid results at a fraction of premium pricing.
Which AI models are most stable for customer support?
GPT-5 Mini and Minimax M2.5 Lightning scored 100% with zero variance. Gemini Pro, DeepSeek Chat, Devstral, and Command-R also showed zero variance. Claude Haiku (±12) and Claude Sonnet (±12) had the highest instability. For production support workflows, stability matters as much as accuracy.
How does OpenMark AI benchmark customer support evaluation?
Ten tests covering platform selection, CRM-native fit, governance, multilingual requirements, and balanced non-absolute reasoning. Scoring uses contains_any and contains_all with partial credit. Higher-point tests require 4-6 concepts in a single answer. Fully deterministic — no LLM-as-judge. Try it yourself for free.
Can OpenMark just do this for me?
Yes — for customer support, the done-for-you audit is from $299 with 48-hour turnaround. Send your task definition, sample inputs, and pass/fail criteria; we benchmark it across all relevant models (up to 30+) and return a report with the recommended primary, fallbacks, and cost projections at your volume. See the audit service →
Why Teams Use OpenMark AI
You define the evaluation in your words, for your use case. Not MMLU, not HumanEval — your actual support scenarios, your actual requirements.
Multiple runs per model with variance tracking. A model that scores 87 once and 75 the next is not the same as one that scores 81 every time.
See which model is cheapest for your task — scored against quality, not just raw price-per-token.
No accounts with OpenAI, Anthropic, or Google required. OpenMark AI handles every API call — just describe your task and run.
Don't want to design the test yourself? Have us run it for you.
If you don't want to design the customer support test yourself or maintain it as new models ship — we run it for you on your data. Send us your task, we benchmark it across all relevant models (up to 30+) and send back a synthesized report with the recommended primary, fallbacks, cost-at-volume, and re-test triggers. From $299, 48-hour turnaround, no call required.
Benchmark AI on Your Support Workflows
Test which model handles YOUR tickets, YOUR escalation rules, YOUR governance requirements.
Build custom benchmarks for any task — text, code, structured output, classification, images, and more.
50 free credits — no API keys, no setup.