Best AI for RAG
in 2026
Top 29 AI models benchmarked on retrieval-augmented generation with agentic multi-document reasoning — temporal logic, arithmetic aggregation, dependency resolution, contradiction handling, and cross-document reconciliation. No model broke 82%. The hardest benchmark category yet.
What This Benchmark Tests (and Does Not Test)
All models tested with default API configurations. Synthetic documents are embedded directly in each prompt — this tests the model's reasoning ability over provided context, not its retrieval system. 11 of 29 models failed to complete all tests. Scoring is strict: exact answers only, no partial credit.
Benchmark Results
Key Findings
🏆 No Model Broke 82% — The Hardest Benchmark Yet
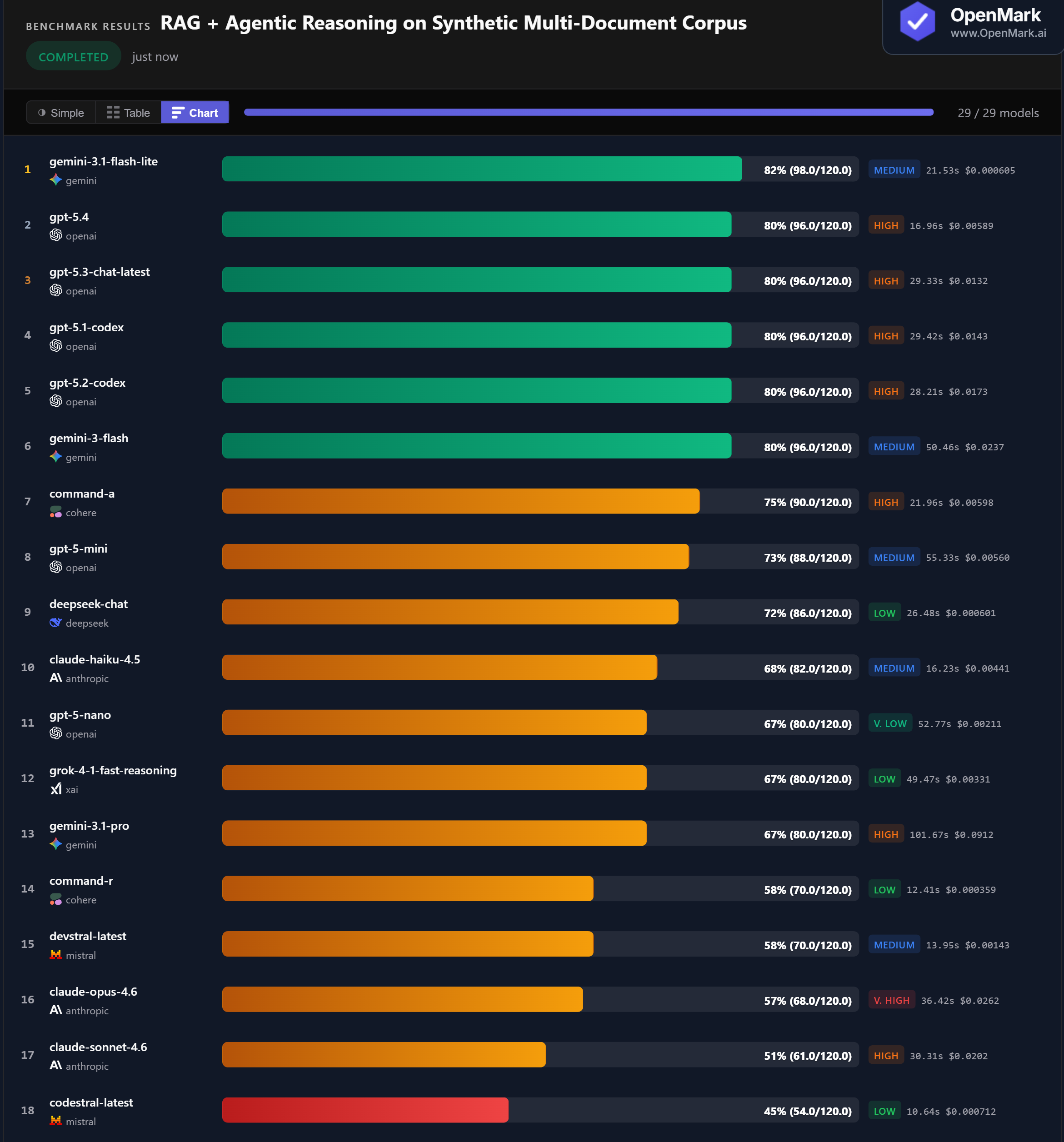
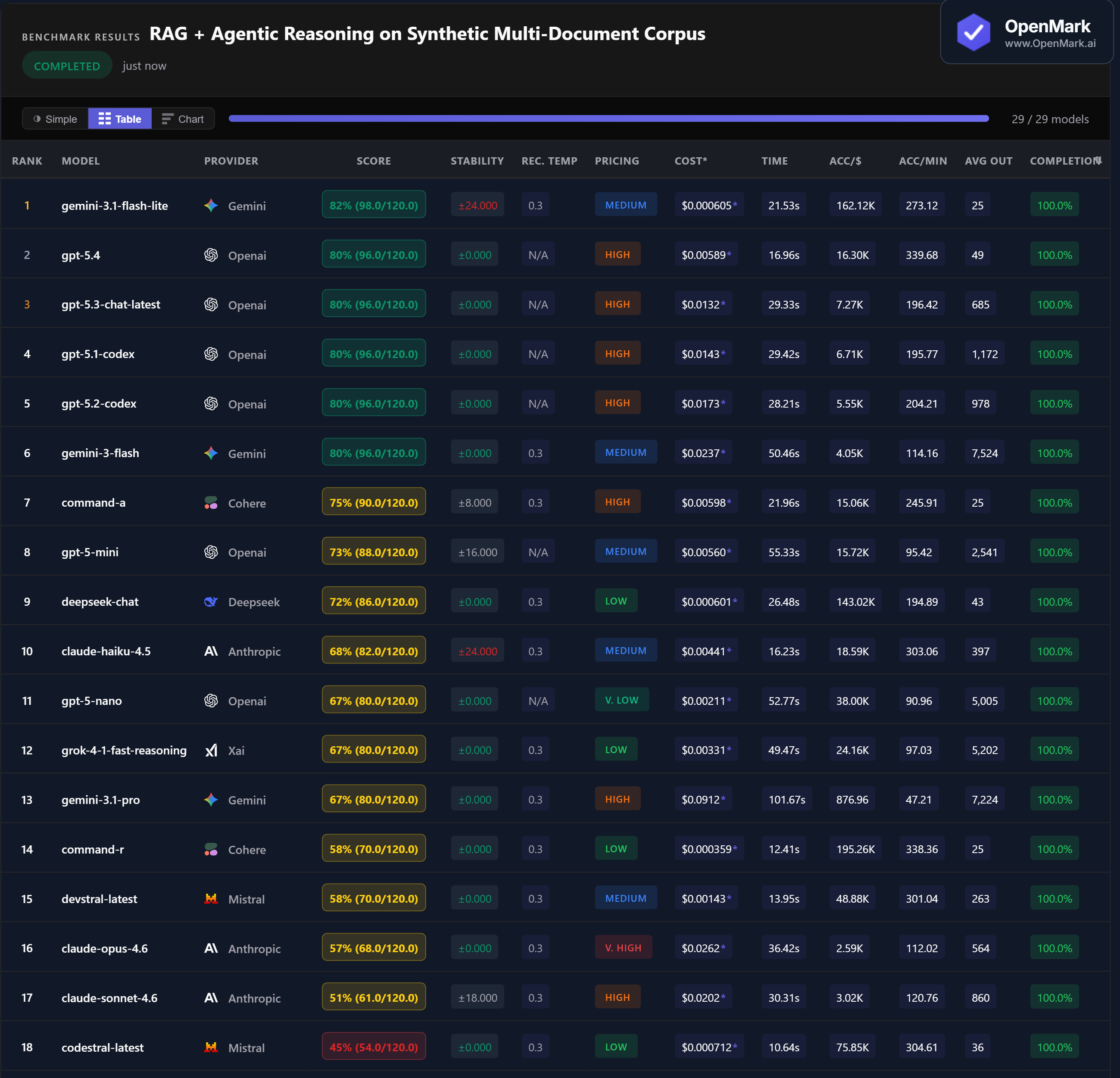
Gemini 3.1 Flash Lite led at 82% (98.0/120.0), but with ±24 variance. Four GPT models — GPT-5.4, GPT-5.3, GPT-5.1 Codex, and GPT-5.2 Codex — all tied at 80% with perfect stability (±0.000). Gemini Flash also hit 80% with zero variance. The 82% ceiling makes RAG + agentic reasoning the hardest benchmark category we have tested — no model aced the cross-document reconciliation or dependency resolution tests consistently.
💰 DeepSeek Chat: 72% Stable RAG for $0.0006
DeepSeek Chat scored 72% at $0.000601/run with zero variance — the best stable budget option at 143,023 Acc/$. Flash Lite scored higher at 82% for nearly the same cost ($0.000605), but with ±24 variance making it unreliable for production. GPT-5-Nano scored 67% at $0.00211 with zero variance. For teams that need reliable RAG at minimal cost, DeepSeek Chat is the clear choice.
⚡ GPT-5.4: Fastest Top Performer at 17 Seconds
GPT-5.4 scored 80% in 16.96 seconds — the fastest model among the top performers, at 340 Acc/min. Codestral was the fastest overall at 10.6 seconds but scored only 45%. Command-R was 12.4 seconds but scored 58%. Among the 80% cluster, GPT-5.4 was 1.7x faster than GPT-5.3 (29.3s) and 3x faster than Gemini Flash (50.5s). For latency-sensitive RAG pipelines, GPT-5.4 offers the best speed-accuracy combination.
📉 Claude Models Struggle: Opus 57%, Sonnet 51%, Haiku 68%
The entire Anthropic family underperformed on RAG — the largest gap vs. GPT in any benchmark category. Claude Opus 4.6 (Very High tier, $0.026/run) scored 57%, 23 points behind the GPT cluster at 80%. Claude Sonnet scored 51% with ±18 variance. Claude Haiku scored 68% but with ±24 variance. Meanwhile, Gemini Pro — also a flagship — scored 67% at 80% the cost of Opus. Multi-document agentic reasoning is a clear weakness for Claude models.
Why These Results May Surprise You
A budget model leading the chart. Premium flagships near the bottom. The cheapest model nearly matching the most expensive. Here is why:
RAG + agentic reasoning is the benchmark category where model marketing claims diverge most from reality. Every model claims to handle documents well. On strict, deterministic scoring with compound reasoning, no model reaches even 85%.
Generic Benchmarks vs. Custom Benchmarks
These results are a directional signal, not a universal RAG ranking. This benchmark tests reasoning over synthetic documents embedded in prompts — it does not test vector search quality, chunking strategies, embedding models, or production RAG pipeline architecture. A model that scores well here may still underperform with a poorly configured retrieval layer.
The practical takeaway: GPT-5.4 is the best all-around choice — 80% accuracy, zero variance, fastest speed (17s), and reasonable cost ($0.006). For budget RAG, DeepSeek Chat (72%, zero variance, $0.0006) delivers reliable results at 1/10th the cost. Avoid Claude models for multi-document agentic tasks — they trail GPT by 12-29 points.
These results are valid for this task design and scoring setup. Change the document complexity, the reasoning steps, or the scoring tolerance, and rankings can change — which is exactly why custom benchmarking matters.
Frequently Asked Questions
Which AI model is best for RAG in 2026?
On our benchmark, Gemini Flash Lite led at 82% but with high variance (±24). Four GPT models tied at 80% with perfect stability — GPT-5.4 was the fastest at 17 seconds. No model broke 82%, making RAG the hardest benchmark category. The best choice depends on whether you prioritize peak accuracy or consistency. Run your own RAG benchmark to find out.
Why is RAG so hard for AI models?
RAG with agentic reasoning requires multiple skills simultaneously: fact retrieval, arithmetic, temporal logic, dependency resolution, constraint filtering, and cross-document reconciliation with stacking rules. The hardest test (24 points) requires 6+ sequential reasoning steps across 4 documents. Most models break at step 4 or 5.
What is the cheapest AI for RAG tasks?
DeepSeek Chat scored 72% at $0.000601/run with zero variance — the best stable budget option. Gemini Flash Lite scored 82% at nearly the same price but with ±24 variance. For reliable RAG at minimal cost, DeepSeek Chat is the stronger choice. Command-R scored 58% at $0.000359 for the highest raw cost efficiency.
Is GPT or Claude better for RAG?
GPT models significantly outperform Claude on RAG. Four GPT models scored 80% with zero variance. Claude Haiku scored 68% (±24), Opus 57%, Sonnet 51% (±18). The gap is 12-29 points — one of the largest between the two families across any benchmark category we have tested.
How does OpenMark AI benchmark RAG?
Ten tests with synthetic documents embedded in prompts, escalating from simple retrieval (5 points) to cross-document reconciliation with stacking rules (24 points). Scoring is strict: exact_match and numeric_from_text with zero tolerance, no partial credit. Fully deterministic — no LLM-as-judge. Try it yourself for free.
Can OpenMark just do this for me?
Yes — for RAG, the done-for-you audit is from $299 with 48-hour turnaround. Send your task definition, sample inputs, and pass/fail criteria; we benchmark it across all relevant models (up to 30+) and return a report with the recommended primary, fallbacks, and cost projections at your volume. See the audit service →
Why Teams Use OpenMark AI
You define the evaluation in your words, for your use case. Not MMLU, not HumanEval — your actual documents, your actual retrieval scenarios.
Multiple runs per model with variance tracking. A model that scores 82 once and 58 the next is not the same as one that scores 80 every time.
See which model is cheapest for your task — scored against quality, not just raw price-per-token.
No accounts with OpenAI, Anthropic, or Google required. OpenMark AI handles every API call — just describe your task and run.
Don't want to design the test yourself? Have us run it for you.
If you don't want to design the RAG test yourself or maintain it as new models ship — we run it for you on your data. Send us your task, we benchmark it across all relevant models (up to 30+) and send back a synthesized report with the recommended primary, fallbacks, cost-at-volume, and re-test triggers. From $299, 48-hour turnaround, no call required.
Benchmark AI on Your RAG Pipeline
Test which model reasons best over YOUR documents, YOUR retrieval scenarios, YOUR data.
Build custom benchmarks for any task — text, code, structured output, classification, images, and more.
50 free credits — no API keys, no setup.