Best AI for Content Creation
in 2026
Top 30 AI models benchmarked on content creation — social media hooks, ad copy, blog writing, persona messaging, campaign taglines, and full-funnel frameworks. Minimax scored a perfect 100%, but GPT-5.4 Nano matched Grok-4 at 93% for 29x less cost. 22 models scored above 77%.
What This Benchmark Tests (and Does Not Test)
All models tested with default API configurations. Scoring checks for required marketing concepts and structural elements — it validates completeness and relevance, not subjective creative quality. 8 of 30 models failed to complete all tests or had very low completion rates.
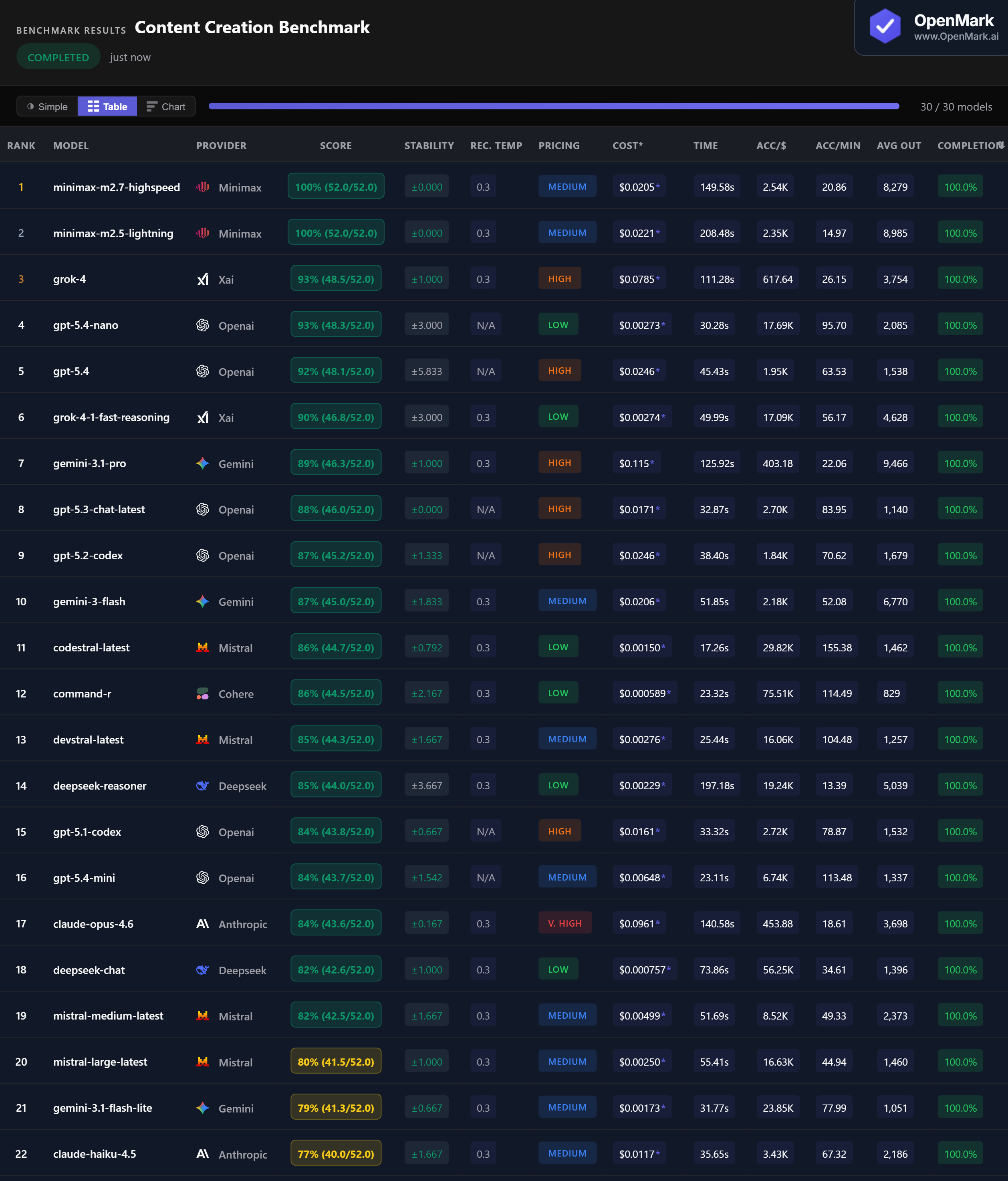
Benchmark Results

Key Findings
🏆 Two Perfect Scores From Minimax — With Zero Variance
Both Minimax M2.7 Highspeed and Minimax M2.5 Lightning scored 100% (52.0/52.0) with zero variance. Both are Medium-tier models at around $0.02/run. M2.7 Highspeed was faster at 150 seconds vs 208 seconds for M2.5 — the speed variant lives up to its name without sacrificing accuracy. No other model achieved a perfect score on content creation.
💰 GPT-5.4 Nano: 93% at $0.003 — The Budget Powerhouse
GPT-5.4 Nano scored 93% at $0.00273/run — matching Grok-4 (93%) which costs $0.079, a 29x price difference. It was also 3.7x faster at 30 seconds. At 17,686 Acc/$, GPT-5.4 Nano offers the best balance of quality and cost for content creation. For teams generating marketing content at scale, this is the standout option — near-flagship accuracy at budget pricing.
⚡ Codestral: Fastest Content Creator at 17 Seconds
Codestral scored 86% in 17.3 seconds — the fastest model in the benchmark at 155 Acc/min. At $0.0015/run (Low tier), it combines speed and cost efficiency for high-volume content workflows. Command-R was nearly as fast at 23 seconds with 86% and lower cost ($0.0006). For latency-critical content pipelines, these two models deliver 86% accuracy in under 25 seconds at under $0.002/run.
📉 Claude Opus ($0.096) Trails GPT-5.4 Nano ($0.003) by 9 Points
Claude Opus 4.6 scored 84% at $0.096/run — Very High pricing for a mid-pack result. GPT-5.4 Nano scored 93% at 35x less cost. Claude Haiku scored only 77% — the lowest among all models that completed the benchmark. Claude Sonnet 4.6 managed just 64% with 45% completion. Across Anthropic's lineup, content creation is not a strength — all three models were outperformed by budget alternatives from every other provider.
Why These Results May Surprise You
A coding model scoring 86% on marketing content. Budget models outperforming premium flagships. Near-universal competence across providers. Here is why:
Content creation is the most accessible benchmark category — nearly every model can write decent marketing copy. The differentiator is completeness: can the model include all 10 required concepts in a full-funnel campaign framework, or does it drop a few?
Generic Benchmarks vs. Custom Benchmarks
These results are a directional signal, not a universal content creation ranking. This benchmark tests concept coverage and structural completeness — it does not evaluate creative quality, brand voice, tone, persuasiveness, or visual design integration. A model that scores 100% here may still produce generic copy that misses your brand's voice.
The practical takeaway: GPT-5.4 Nano is the best value — 93% accuracy at $0.003/run, 30 seconds, Low-tier pricing. For perfect scores, Minimax delivers at $0.02/run but is slower. For speed-critical workflows, Codestral (86%, 17 seconds) and Command-R (86%, 23 seconds) are the fastest options under $0.002. Content creation is one of the few categories where budget models genuinely rival flagships.
These results are valid for this task design and scoring setup. Change the content types, the brand voice requirements, or the evaluation criteria, and rankings can change — which is exactly why custom benchmarking matters.
Frequently Asked Questions
Which AI model is best for content creation in 2026?
On our benchmark, both Minimax models scored a perfect 100% with zero variance. Grok-4 and GPT-5.4 Nano tied at 93%, but GPT-5.4 Nano costs 29x less. Content creation is competitive — 22 models scored above 77%. The best choice depends on your budget and speed requirements. Run your own content benchmark to find out.
Can AI write good marketing copy?
Yes — 22 of 30 models scored above 77% on tasks including social hooks, ad copy, blog intros, persona messaging, and full-funnel frameworks. Even budget models like Command-R (86%) and Codestral (86%) performed strongly. Content creation is the most accessible AI benchmark category, with low variance across most models.
What is the cheapest AI for content creation?
Command-R scored 86% at $0.000589/run — the highest cost efficiency at 75,507 Acc/$. GPT-5.4 Nano scored 93% at $0.00273 for the best quality-per-dollar balance. Codestral scored 86% at $0.00150 and was the fastest model at 17 seconds. All outperform Claude Opus ($0.096, 84%) at a fraction of the price.
Is AI content creation reliable across runs?
Content creation showed the lowest variance of any benchmark category. Both Minimax models and GPT-5.3 had zero variance. Most models showed ±0-3 variance. This makes content creation one of the most reliable AI use cases — you can expect consistent output quality across runs.
How does OpenMark AI benchmark content creation?
Ten tasks covering social hooks, email subject lines, ad copy, blog intros, persona messaging, taglines, launch messaging, content briefs, multi-format campaigns, and full-funnel frameworks. Scoring uses contains_all with partial credit to check for required marketing concepts. Fully deterministic — no LLM-as-judge. Try it yourself for free.
Why Teams Use OpenMark AI
You define the evaluation in your words, for your use case. Not MMLU, not HumanEval — your actual content briefs, your actual brand requirements.
Multiple runs per model with variance tracking. A model that scores 92 once and 80 the next is not the same as one that scores 86 every time.
See which model is cheapest for your task — scored against quality, not just raw price-per-token.
No accounts with OpenAI, Anthropic, or Google required. OpenMark AI handles every API call — just describe your task and run.
Benchmark AI on Your Content Workflows
Test which model writes the best copy for YOUR brand, YOUR audience, YOUR campaigns.
Build custom benchmarks for any task — text, code, structured output, classification, images, and more.
50 free credits — no API keys, no setup.