Best AI for Academic Research
in 2026
Top 29 AI models benchmarked on academic research reasoning — hypothesis generation, study design, statistical interpretation, causal analysis, RCT design, and structured research plans. Gemini 3.1 Pro led at 82%, but Flash Lite matched at 80% for 98x less cost. No model broke 82%.
What This Benchmark Tests (and Does Not Test)
All models tested with default API configurations. This benchmark evaluates whether a model can demonstrate structured academic reasoning — identifying correct study designs, interpreting statistics, and producing formatted research plans — under strict output constraints. It tests reasoning precision, not the ability to conduct or publish actual research. 8 of 29 models failed to complete all tests.
Benchmark Results
Key Findings
🏆 Gemini 3.1 Pro Leads at 82% With Perfect Stability
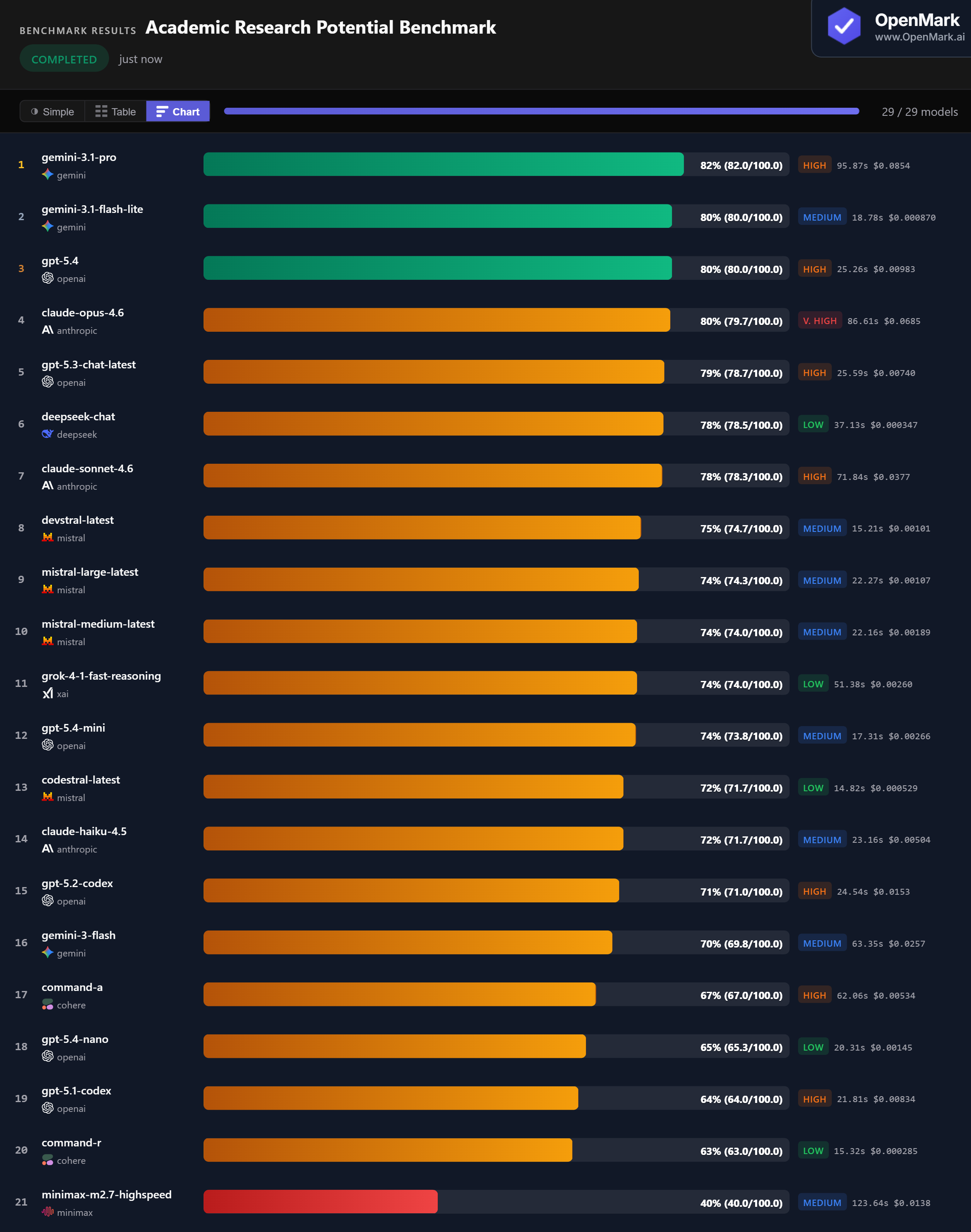
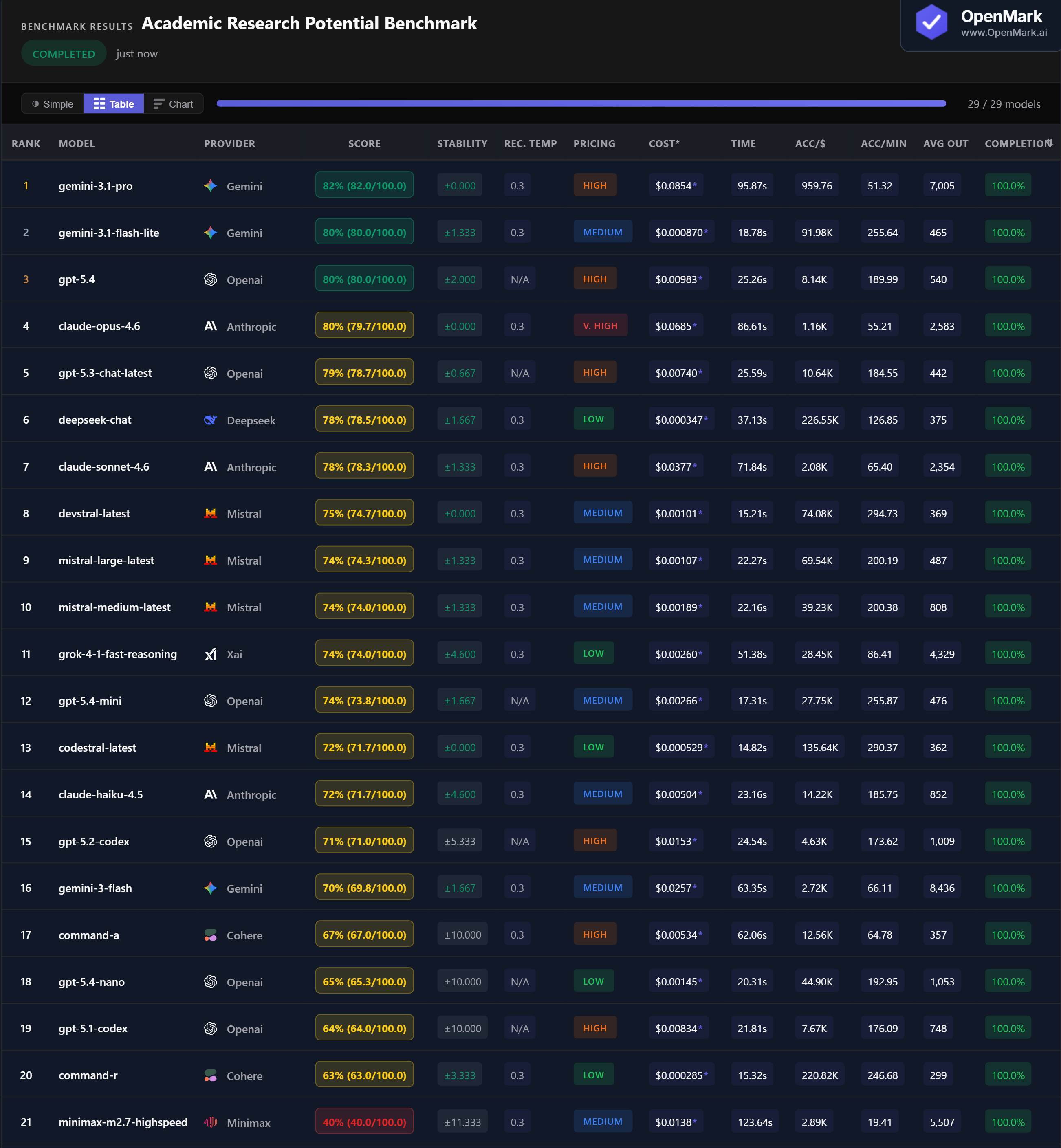
Gemini 3.1 Pro scored 82% (82.0/100.0) with zero variance — the only model to break 80% consistently. As a strong reasoning model, its lead on an academic research benchmark validates the task design. Flash Lite and GPT-5.4 tied at 80%, and Claude Opus also hit 80%. The top 4 are tightly clustered, but Gemini Pro's zero variance makes it the most reliable choice for research-grade reasoning.
💰 DeepSeek Chat: 78% Research Reasoning for $0.00035
DeepSeek Chat scored 78% at $0.000347/run — the highest cost efficiency at 226,551 Acc/$. It matched Claude Sonnet (78%, $0.038/run) at 108x less cost. Gemini Flash Lite scored 80% at $0.00087 — matching GPT-5.4 ($0.0098) at 11x less cost. For researchers running repeated queries, these budget models deliver near-top-tier academic reasoning for pennies.
⚡ Devstral and Codestral: Fast Research Reasoning in 15 Seconds
Devstral scored 75% in 15.2 seconds with zero variance (295 Acc/min). Codestral scored 72% in 14.8 seconds, also with zero variance (290 Acc/min). Both are Mistral models at Medium/Low pricing. For latency-sensitive research pipelines — literature screening, batch hypothesis evaluation — these two deliver 70%+ accuracy faster than any other model. GPT-5.4 Mini (74%, 17.3s) is another strong fast option.
📉 GPT-5.4 Pro Timed Out at $0.48 Per Run
GPT-5.4 Pro — the most expensive model at $0.476/run — completed only 40% of tests before timing out at 326 seconds. It scored 41% on what it managed to finish. By contrast, Gemini Flash Lite scored 80% in 19 seconds for $0.00087. The premium "Pro" model was 547x more expensive and 17x slower, yet scored half as much. DeepSeek Reasoner, another reasoning-focused model, also struggled at 15% with 20% completion. Slower reasoning models that generate extensive chain-of-thought often fail under time and format constraints.
Why These Results May Surprise You
A budget model matching Anthropic's flagship. The most expensive model timing out. A coding model scoring 72% on academic research. Here is why:
The results confirm that academic research reasoning is best served by models that combine domain knowledge of research methodology with precise, concise output under format constraints. Extended reasoning is a liability when time and format compliance are the bottleneck.
Generic Benchmarks vs. Custom Benchmarks
These results are a directional signal, not a universal academic research ranking. This benchmark tests whether models can demonstrate structured reasoning about research methodology — naming study designs, interpreting statistics, identifying validity threats, and producing formatted research plans. It does not test literature search, novel insight generation, writing quality, or actual research output.
The practical takeaway: Gemini Flash Lite is the standout value — 80% accuracy at $0.00087/run, 19 seconds, with low variance. For researchers on a budget, DeepSeek Chat (78%, $0.00035) delivers near-identical results at even lower cost. Gemini Pro (82%) is the accuracy leader, but the 2-point gap over Flash Lite comes at 98x the cost.
These results are valid for this task design and scoring setup. A benchmark testing different research skills — literature synthesis, experimental creativity, writing quality — would likely produce different rankings. Which is exactly why custom benchmarking matters.
Frequently Asked Questions
Which AI model is best for academic research in 2026?
On our benchmark, Gemini 3.1 Pro led at 82% with zero variance. Flash Lite and GPT-5.4 tied at 80%, with Flash Lite costing 98x less. The benchmark tests structured academic reasoning — hypothesis generation, study design, and statistical interpretation — not actual research output. Run your own research benchmark to find out what works for your use case.
What does this benchmark actually test?
Structured academic reasoning under format constraints: identifying confounders, naming study designs, interpreting p-values, recognizing mediation, interpreting regression coefficients, and producing a JSON research plan. It tests whether a model knows research methodology terminology and can produce precise, formatted answers. It does not test literature search, creative insight, or real research output.
What is the cheapest AI for academic research tasks?
DeepSeek Chat scored 78% at $0.000347/run — the highest cost efficiency at 226,551 Acc/$. It matched Claude Sonnet's score at 108x less cost. Gemini Flash Lite scored 80% at $0.000870. Codestral scored 72% at $0.000529. All outperform models costing 20-200x more.
Why did GPT-5.4 Pro score so low?
GPT-5.4 Pro generated extensive chain-of-thought responses, taking 326 seconds and completing only 40% of tests before timing out. At $0.476/run, it was by far the most expensive model with the least completion. Slower reasoning models can fail benchmarks that enforce time and format constraints, even if their underlying reasoning ability is strong.
How does OpenMark AI benchmark academic research?
Ten tests covering confounder identification, hypothesis formulation, study design, p-value interpretation, validity threats, construct operationalization, mediation, regression interpretation, RCT design, and a structured JSON research plan. Scoring uses exact_match, contains_all, and json_schema with regex validation. Fully deterministic — no LLM-as-judge. Try it yourself for free.
Can OpenMark just do this for me?
Yes — for academic research, the done-for-you audit is from $299 with 48-hour turnaround. Send your task definition, sample inputs, and pass/fail criteria; we benchmark it across all relevant models (up to 30+) and return a report with the recommended primary, fallbacks, and cost projections at your volume. See the audit service →
Why Teams Use OpenMark AI
You define the evaluation in your words, for your use case. Not MMLU, not HumanEval — your actual research questions, your actual methodology requirements.
Multiple runs per model with variance tracking. A model that scores 80 once and 47 the next is not the same as one that scores 74 every time.
See which model is cheapest for your task — scored against quality, not just raw price-per-token.
No accounts with OpenAI, Anthropic, or Google required. OpenMark AI handles every API call — just describe your task and run.
Don't want to design the test yourself? Have us run it for you.
If you don't want to design the academic research test yourself or maintain it as new models ship — we run it for you on your data. Send us your task, we benchmark it across all relevant models (up to 30+) and send back a synthesized report with the recommended primary, fallbacks, cost-at-volume, and re-test triggers. From $299, 48-hour turnaround, no call required.
Benchmark AI on Your Research Tasks
Test which model handles YOUR methodology questions, YOUR statistical interpretations, YOUR research designs.
Build custom benchmarks for any task — text, code, structured output, classification, images, and more.
50 free credits — no API keys, no setup.