Best AI for Chatbots
in 2026
Top 29 AI models benchmarked on chatbot potential — de-escalation, safety, summarization, memory, structured extraction, contradiction detection, crisis response, and planning. Gemini Flash and DeepSeek Chat tied at 78%, but DeepSeek costs 38x less. No model broke 78%.
What This Benchmark Tests (and Does Not Test)
All models tested with default API configurations. This benchmark evaluates core chatbot skills — safety, extraction, memory, and structured responses — in single-turn format. It does not test extended multi-turn conversations or subjective interaction quality. 7 of 29 models failed to complete all tests or showed extreme instability.
Benchmark Results
Key Findings
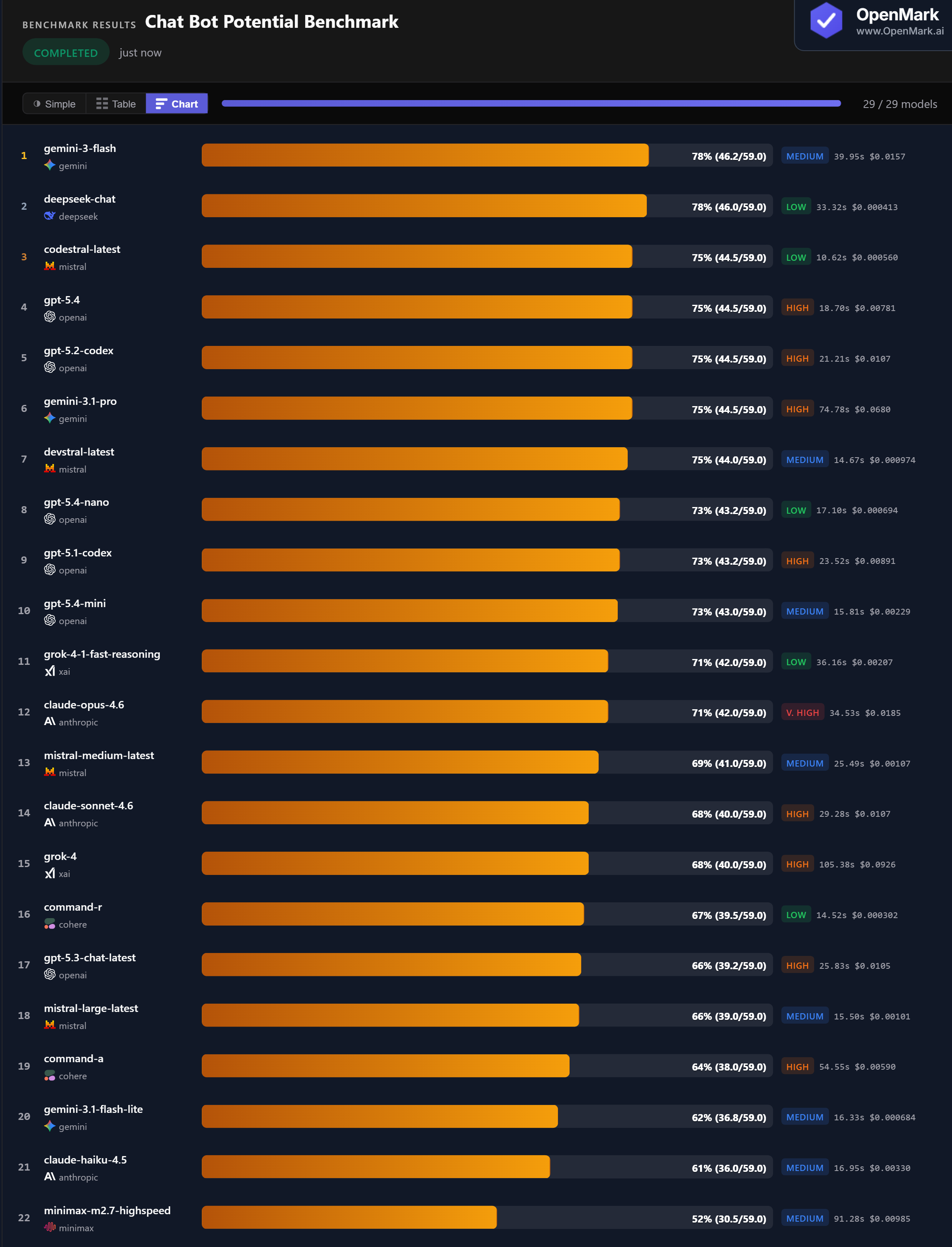
🏆 DeepSeek Chat: Best Value Chatbot at 78% for $0.0004
DeepSeek Chat tied for first at 78% (46.0/59.0) with zero variance — at $0.000413/run, it costs 38x less than co-leader Gemini Flash ($0.0157). At 111,380 Acc/$, DeepSeek Chat offers the highest cost efficiency among top performers. Gemini Flash scored marginally higher (46.2 vs 46.0) but with ±2.5 variance. For production chatbots where cost and consistency both matter, DeepSeek Chat is the clear winner.
⚡ Codestral: Fastest Chatbot at 10.6 Seconds
Codestral scored 75% in 10.6 seconds with zero variance — 251 Acc/min, the fastest model by a wide margin. At $0.000560/run (Low tier), it combines speed, stability, and cost efficiency. Command-R followed at 14.5 seconds (67%), Devstral at 14.7 seconds (75%). For chatbots where response latency directly impacts user experience, sub-15-second models are the strongest choices. The leaders at 78% (Gemini Flash, DeepSeek) are 3-4x slower.
📊 GPT-5.3 Chat Scores Lower Than Every Other GPT Model
GPT-5.3 Chat — OpenAI's dedicated chat model — scored 66%, the lowest among all GPT models on this chatbot benchmark. GPT-5.4 scored 75%, GPT-5.2 Codex scored 75%, GPT-5.4 Nano scored 73%, GPT-5.4 Mini scored 73%, and GPT-5.1 Codex scored 73%. The "chat-optimized" model was outperformed by every sibling, including coding-focused models. Model naming does not predict task performance.
📉 Premium Models Trail Budget Alternatives Across the Board
Claude Opus ($0.019) scored 71% — beaten by DeepSeek Chat ($0.0004) by 7 points at 45x less cost. Gemini Pro ($0.068) scored 75% — matched by Codestral ($0.0006) at 121x less cost. Grok-4 ($0.093) scored just 68%. Claude Haiku scored 61%, the lowest among all Anthropic models. For chatbot deployments at scale, every premium model is outperformed on accuracy-per-dollar by budget alternatives.
Why These Results May Surprise You
A coding model among the top chatbot performers. The dedicated "chat" model scoring lowest in its family. Budget models dominating the leaderboard. Here is why:
Chatbot potential benchmarks reward well-rounded models that follow instructions precisely across diverse task types. The results make clear that model naming ("Chat," "Pro") does not predict chatbot performance — multi-skill competence does.
Generic Benchmarks vs. Custom Benchmarks
These results are a directional signal, not a universal chatbot ranking. This benchmark tests core chatbot skills in single-turn format — it does not evaluate multi-turn conversation flow, personality consistency, tone adaptation, or real-time streaming performance.
The practical takeaway: DeepSeek Chat is the best overall choice — 78% accuracy, zero variance, $0.0004/run. For speed-critical chatbots, Codestral (75%, 10.6 seconds, zero variance) is the fastest option. For a balance of speed and accuracy at a moderate cost, GPT-5.4 Mini (73%, 15.8 seconds, $0.002) is a strong alternative.
These results are valid for this task design and scoring setup. Change the conversation scenarios, the safety requirements, or the scoring criteria, and rankings can change — which is exactly why custom benchmarking matters.
Frequently Asked Questions
Which AI model is best for chatbots in 2026?
On our benchmark, Gemini Flash and DeepSeek Chat tied at 78%. DeepSeek Chat is the value pick: zero variance, $0.0004/run, 38x cheaper than Gemini Flash. Five models tied at 75% including Codestral (fastest at 10.6s) and GPT-5.4 (zero variance). Run your own chatbot benchmark to find the best fit for your use case.
What skills does a chatbot AI need?
This benchmark tests 10 skills: de-escalation, privacy safety, clarifying questions, summarization, JSON extraction, bug prioritization, multi-turn memory, contradiction detection, crisis response, and structured planning. No model scored above 78%, making chatbot potential one of the most demanding multi-skill benchmarks.
What is the cheapest AI for chatbots?
DeepSeek Chat scored 78% at $0.000413/run with zero variance (111,380 Acc/$). Codestral scored 75% at $0.000560 and was the fastest at 10.6s. Command-R scored 67% at $0.000302. All three outperform Claude Opus ($0.019, 71%) at a fraction of the cost.
Which AI chatbot model is fastest?
Codestral was fastest at 10.6 seconds (75%, zero variance, 251 Acc/min). Command-R followed at 14.5 seconds (67%). Devstral was 14.7 seconds (75%). For chatbots where response latency matters, these sub-15-second models are the strongest options.
How does OpenMark AI benchmark chatbot potential?
Ten tests covering MCQ safety scenarios, ticket summarization, JSON extraction, bug prioritization, multi-turn memory, contradiction detection, crisis response, and structured JSON planning. Scoring uses exact_match, contains_all, json_schema, and numeric_from_text. Fully deterministic — no LLM-as-judge. Try it yourself for free.
Why Teams Use OpenMark AI
You define the evaluation in your words, for your use case. Not MMLU, not HumanEval — your actual chat scenarios, your actual safety requirements.
Multiple runs per model with variance tracking. A model that scores 78 once and 65 the next is not the same as one that scores 75 every time.
See which model is cheapest for your task — scored against quality, not just raw price-per-token.
No accounts with OpenAI, Anthropic, or Google required. OpenMark AI handles every API call — just describe your task and run.
Benchmark AI on Your Chatbot Scenarios
Test which model handles YOUR conversations, YOUR safety rules, YOUR extraction formats.
Build custom benchmarks for any task — text, code, structured output, classification, images, and more.
50 free credits — no API keys, no setup.